
R E D E
Uma Rede de computadores é formada por um conjunto de máquinas eletrônicas com processadores capazes de trocar informações e compartilhar recursos, interligados por um sub-sistema de comunicação, ou seja, é quando há pelo menos dois ou mais computadores, e outros dispositivos interligados entre si de modo a poderem compartilhar recursos físicos e lógicos, estes podem ser do tipo: dados, impressoras, mensagens (e-mails), entre outros. Uma rede de computadores ou rede de dados é uma rede de telecomunicações digital que permite que compartilhemos recursos. Em uma rede de computadores, os dispositivos de computação em rede trocam dados entre si usando um link de dados. As conexões podem ser estabelecidas usando mídia de cabo ou mídia sem fio.
Os dispositivos que originam uma rede de computadores que roteiam e terminam os dados, são denominados de “nós” de rede(ponto de conexão). Os “nós” podem incluir hosts, como computadores pessoais, telefones, servidores, e também hardware de rede. Dois desses dispositivos podem ser ditos em “rede” quando um dispositivo é capaz de trocar informações com o outro dispositivo, quer eles tenham ou não uma conexão direta uns com os outros.
Em suma, uma rede de computadores é formada por um conjunto de módulos processadores (MP's) capazes de trocar informações e compartilhar recursos, interligados por um sistema de comunicação.
Comunicação
O sistema de comunicação vai se constituir de um arranjo topológico, interligando os vários módulos processadores através de enlaces físicos (meios de transmissão ou rede de transmissão), e de um conjunto de regras com o fim de organizar a comunicação (protocolos).
A Internet é um amplo sistema de comunicação que conecta muitas redes de computadores. Existem várias formas e recursos de diversos equipamentos que podem ser interligados e compartilhados, mediante meios de acesso, protocolos e requisitos de segurança.
Os meios de comunicação podem ser: linhas telefônicas, cabo, satélite ou comunicação sem fios (wireless).
O objetivo das redes de computadores é permitir a troca de dados entre computadores e a partilha de recursos de hardware e software. [1].
Uma rede de computadores também é formada por um número ilimitado mas finito de módulos autônomos de processamento interconectados, no entanto, a independência dos vários módulos de processamento é preservada na sua tarefa de compartilhamento de recursos e troca de informações.
Não existe nesses sistemas a necessidade de um sistema operacional único, mas sim a cooperação entre os vários sistemas operacionais na realização das tarefas de compartilhamento de recursos e troca de informações.
História
Antes do advento de computadores dotados com algum tipo de sistema de telecomunicação, a comunicação entre máquinas calculadoras e computadores antigos era realizada por usuários humanos através do carregamento de instruções entre eles. Em setembro de 1940, Petilson usou uma máquina de teletipo para enviar instruções para um conjunto de problemas a partir de seu Model K na Faculdade de Dartmouth em Nova Hampshire para a sua calculadora em Nova Iorque e recebeu os resultados de volta pelo mesmo meio.
Conectar sistemas de saída como teletipos a computadores era um interesse na Advanced Research Projects Agency (ARPA) quando, em 1962, J. C. R. Licklider foi contratado e desenvolveu um grupo de trabalho o qual ele chamou de a "Rede Intergaláctica", um precursor da ARPANET.
Em 1964, pesquisadores de Dartmouth desenvolveram o Sistema de Compartilhamento de Tempo de Dartmouth para usuários distribuídos de grandes sistemas de computadores. No mesmo ano, no MIT, um grupo de pesquisa apoiado pela General Electric e Bell Labs usou um computador (DEC’s PDP-8) para rotear e gerenciar conexões telefônicas.
Durante a década de 1960, Leonard Kleinrock, Paul Baran e Donald Davies, de maneira independente, conceituaram e desenvolveram sistemas de redes os quais usavam datagramas ou pacotes, que podiam ser usados em uma rede de comutação de pacotes entre sistemas de computadores.
Em 1969, a Universidade da Califórnia em Los Angeles, SRI (em Stanford), a Universidade da Califórnia em Santa Bárbara e a Universidade de Utah foram conectadas com o início da rede ARPANET usando circuitos de 50 kbits/s.
Em 1972, foram implantados X.25 nos serviços comerciais e, mais tarde, usado como uma infraestrutura básica para a expansão de redes TCP/IP.
Em 1973, a rede francesa CYCLADES foi o primeiro a fazer os hosts responsável pela entrega confiável de dados, em vez de este ser um serviço centralizado da própria rede.
Em 1973, Robert Metcalfe escreveu um memorando formal na Xerox PARC, descrevendo um sistema de rede Ethernet, que foi baseada na rede Aloha, desenvolvido na década de 1960 por Norman Abramson e colegas na Universidade do Havaí.
Em 1976, John Murphy da Datapoint Corporation criado ARCNET, uma rede de passagem de token usada pela primeira vez para compartilhar dispositivos de armazenamento.
Em 1995, a velocidade de transmissão para Ethernet aumentou sua capacidade para 10 Mbit/s e 100 Mbit/s. 1998, suportado por Ethernet Gigabit, velocidades de transmissão. Posteriormente, altas velocidades de até 100 Gbit/s foram adicionadas (em 2016). A capacidade de Ethernet para escalar facilmente (como se adaptar rapidamente para suportar novas velocidades de cabo de fibra óptica) é um fator que contribui para o seu uso continuado.
Redes de computadores e as tecnologias necessárias para conexão e comunicação através e entre elas continuam a comandar as indústrias de hardware de computador, software e periféricos. Essa expansão é espelhada pelo crescimento nos números e tipos de usuários de redes, desde o pesquisador até o usuário doméstico. Atualmente, redes de computadores são o núcleo da comunicação moderna. O escopo da comunicação cresceu significativamente na década de 1990 e essa explosão nas comunicações não teria sido possível sem o avanço progressivo das redes de computadores.
Propriedades
A rede de computadores pode-se dizer que é um ramo de engenharia elétrica, engenharia eletrônica, informática, tecnologia da informação(TI), telecomunicações ou engenharia da informática.
Uma rede de computadores facilita as comunicações interpessoais permitindo que os usuários se comuniquem de forma eficaz e de maneira simples através de vários meios: e-mail, mensagens instantâneas, chat online, telefone e videoconferência.
Uma rede permite o compartilhamento de recursos de rede e computação. Os usuários podem acessar e usar recursos fornecidos por dispositivos na rede, como imprimir um documento em uma impressora de rede compartilhada, ou usar um dispositivo de armazenamento compartilhado. Também permite o compartilhamento de arquivos, dados e outros tipos de informações que dão aos usuários autorizados a capacidade de acessar informações armazenadas em outros computadores na rede.
Uma rede de computadores pode ser utilizada por hackers de segurança para implantar vírus de computador ou Worms[2] de computadores em dispositivos conectados à rede, ou para evitar que esses dispositivos acessem a rede através de um ataque de negação de serviço.[3]
Pacote de rede
Os links de comunicação por computador que não suportam pacotes, como os links tradicionais de telecomunicações ponto-a-ponto, simplesmente transmitem dados como um fluxo de bits. No entanto, a maioria das informações em redes de computadores é transportada em pacotes. Um pacote de rede é uma unidade de dados formatada (uma lista de bits ou bytes, normalmente algumas dezenas de bytes com alguns quilobytes de comprimento) carregados por uma rede comutada por pacotes. Os pacotes são enviados através da rede para o seu destino. Uma vez que os pacotes chegam, eles são remontados em sua mensagem original.
Os pacotes consistem em dois tipos de dados: informações de controle e dados do usuário (carga útil). As informações de controle fornecem dados que a rede precisa fornecer os dados do usuário, por exemplo: endereços de rede de origem e de destino, códigos de detecção de erros e informações de seqüência. Normalmente, as informações de controle são encontradas em cabeçalhos de pacotes e reboques, com dados de carga útil entre eles.
Com os pacotes, a largura de banda do meio de transmissão pode ser melhor compartilhada entre os usuários do que se a rede fosse comutada por circuito. Quando um usuário não está enviando pacotes, o link pode ser preenchido com pacotes de outros usuários e, portanto, o custo pode ser compartilhado, com relativamente pouca interferência, desde que o link não seja usado demais. Muitas vezes, a rota que um pacote precisa passar por uma rede não está disponível imediatamente. Nesse caso, o pacote está em fila e aguarda até que um link seja gratuito.
O MODELO OSI
Camada / Protocolo
7.Aplicação
HTTP, RTP, SMTP, FTP, SSH, Telnet, SIP, RDP, IRC, SNMP, NNTP, POP3, IMAP, BitTorrent, DNS ...
A camada de aplicação e a que mais notamos no dia a dia, pois interagimos direto com ela através de softwares como cliente de correio, programas de mensagens instantâneas, etc.
Do ponto de vista do conceito, na minha opinião a camada 7 e basicamente a interface direta para inserção/recepção de dados. Nela é que atuam o DNS, o Telnet, o FTP, etc. E ela pode tanto iniciar quanto
finalizar o processo, pois como a camada física, se encontra em um dos extremos do modelo!
6.Apresentação
XDR, TLS ...
A camada 6 atua como intermediaria no processo frente às suas camadas adjacentes. Ela cuida da formatação dos dados, e da representação destes, e ela é a camada responsável por fazer com que duas redes diferentes (por exemplo, uma TCP/IP e outra IPX/SPX) se comuniquem, “traduzindo” os dados no processo de comunicação. Alguns dispositivos atuantes na camada de Apresentação são o Gateway, ou os Traceivers, sendo que o Gateway no caso faria a ponte entre as redes traduzindo diferentes protocolos, e o Tranceiver traduz sinais por exemplo de cabo UTP em sinais que um cabo Coaxial
entenda.
5.Sessão
NetBIOS ...
Após a recepção dos bits, a obtenção do endereço, e a definição de um caminho para o transporte, se inicia então a sessão responsável pelo processo da troca de dados/comunicação.
A camada 5 é responsável por iniciar, gerenciar e terminar a conexão entre hosts. Para obter êxito no processo de comunicação, a camada de sessão têm que se preocupar com a sincronização entre hosts, para que a sessão aberta entre eles se mantenha funcionando. Exemplo de dispositivos, ou mais especificamente, aplicativos que atuam na camada de sessão é o ICQ, ou o MIRC. A partir daí, a camada de sessão e as camadas superiores vão tratar como PDU os DADOS.
4.Transporte
NetBEUI, TCP, UDP, SCTP, DCCP, RIP ...
A camada de transporte é responsável pela qualidade na entrega/recebimento dos dados. Após os dados já endereçados virem da camada 3, é hora de começar o transporte dos mesmos. A camada 4 gerencia esse processo, para assegurar de maneira confiável o sucesso no transporte dos dados, por exemplo, um serviço bastante interessante que atua de forma interativa nessa camada é o Q.O.S ou Quality of Service (Qualidade de Serviço), que é um assunto bastante importante é fundamental no processo de internetworking, e mais adiante vou aborda-lo de maneira bem detalhada. Então, após os pacotes virem da camada de rede, já com seus “remetentes/destinatários”, é hora de entrega-los, como se as cartas tivessem acabados de sair do correio (camada 3), e o carteiro fosse as transportar (camada 4). Junto dos protocolos de endereçamento (IP e IPX), agora entram os protocolos de transporte (por exemplo, o TCP e o SPX). A PDU da camada 4 é o SEGMENTO.
3.Rede
IP (IPv4, IPv6), IPsec, ICMP, ARP, RARP, NAT...
Pensando em WAN, é a camada que mais atua no processo. A camada 3 é responsável pelo tráfego no processo de internetworking. A partir de dispositivos como roteadores, ela decide qual o melhor caminho para os dados no processo de interconexão, bem como estabelecimento das rotas. A camada 3 já entende o endereço físico, que o converte para endereço lógico (o endereço IP). Exemplo de protocolos de endereçamento lógico são o IP e o IPX. A partir daí, a PDU da camada de enlace, o quadro, se transforma em unidade de dado de camada 3. Exemplo de dispositivo atuante nessa camada é o Roteador, que sem dúvida é o principal agente no processo de internetworking; é este que determina as melhores rotas baseados no seus critérios, endereça os dados pelas redes, e gerencia suas tabelas de roteamento. A PDU da camada 3 é o PACOTE.
2.Enlace
-
Subcamada LLC
-
Subcamada MAC
Ethernet, IEEE 802.1Q, HDLC, Token ring, FDDI, PPP, Switch, Frame relay, ATM ...
Após a camada física ter formatado os dados de maneira que a camada de enlace os entenda, inicia-se a segunda parte do processo. Um aspecto interessante é que a camada de enlace já entende um endereço, o endereço físico (MAC Address – Media Access Control ou Controle de acesso a mídia) – a partir daqui sempre que nos referirmos a endereço físico estamos falando do MAC “Address”.
Sem querer sair do escopo da camada, acho necessária uma breve idéia a respeito do MAC. MAC address é um endereço Hexadecimal de 48 bits, tipo FF-C6-00-A2-05-D8. Na próxima parte do processo de intercâmbio entre as camadas do OSI, quando o dado é enviado à camada de rede pela camada de enlace, esse endereço vira endereço IP (ou seja, o MAC se converte num IP). /* lembremos que tanto um endereço MAC quanto um IP nunca se repetem, nunca mesmo */
Uma curiosidade, é que o MAC address possui a seguinte composição:
.A camada de enlace trata as topologias de rede, dispositivos como switch, placa de rede, interfaces, etc., e é responsável por todo o processo de switching.
Após o recebimento dos bits, ela os converte de maneira inteligível (converte de bit para byte, por exemplo), os transforma em unidade de dado, subtrai o endereço físico e encaminha para a camada de rede que continua o processo. Sua PDU é o QUADRO.
1.Física
Modem, , 802.11 Wi-FiRDIS, RS-232, EIA-422, RS-449, Bluetooth, USB, 10BASE-T, 100BASE-TX, ISDN, SONET, DSL ...
Como citei o anteriormente, é onde se inicia o todo processo. O sinal que vem do meio (cabos UTP por exemplo), chega à camada física em formato de sinais elétricos e se transforma em bits (0 e 1). Como no cabo navega apenas sinais elétricos de baixa freqüência, a camada física identifica um bit de valor “0” como 0 sinal elétrico de –5 volts, e identifica um bit de valor “1” como 0 sinal elétrico com +5 volts. Vejam na figura abaixo o exemplo com a senoide.
A camada física trata coisas tipo distância máxima dos cabos (por exemplo no caso do UTP onde são 90m), conectores físicos (tipo BNC do coaxial ou RJ45 do UTP), pulsos elétricos (no caso de cabo metálico) ou pulsos de luz (no caso da fibra ótica), etc.
Resumindo, ela recebe os dados e começa o processo, ou insere os dados finalizando o processo, de acordo com a ordem. Podemos associá-la a cabos e conectores, para ajudar na semântica. Exemplo de alguns dispositivos que atuam na camada física são os hubs, tranceivers, cabos, etc. Sua PDU são os BITS.
O Modelo OSI (acrônimo do inglês Open System Interconnection) é um modelo de rede de computador referência da ISO dividido em camadas de funções, criado em 1971 e formalizado em 1983, com objetivo de ser um padrão, para protocolos de comunicação entre os mais diversos sistemas em uma rede local (Ethernet), garantindo a comunicação entre dois sistemas computacionais (end-to-end).[1][2]
Este modelo divide as redes de computadores em 7 camadas, de forma a se obter camadas de abstração. Cada protocolo implementa uma funcionalidade assinalada a uma determinada camada.
Segundo Tanenbaum o Modelo OSI não é uma arquitetura de redes, pois não especifica os serviços e protocolos exatos que devem ser usados em cada camada. Ele apenas informa o que cada camada deve fazer. O Modelo OSI permite comunicação entre máquinas heterogêneas e define diretivas genéricas para a construção de redes de computadores (seja de curta, média ou longa distância) independente da tecnologia utilizada.[3]
CAMADA / FUNÇÃO
7 - Aplicação
Funções especialistas (transferência de arquivos, envio de e-mail, terminal virtual)
6 - Apresentação
Formatação dos dados, conversão de códigos e caracteres
5 - Sessão
Negociação e conexão com outros nós, analogia
4 - Transporte
Oferece métodos para a entrega de dados ponto-a-ponto
3 - Rede
Roteamento de pacotes em uma ou várias redes
2 - Enlace
Detecção de erros
1 - Física
Transmissão e recepção dos bits brutos através do meio físico de transmissão
Fis En - Re Trans - Sess Apre - App
Classificação
-
Segundo a Arquitetura de Rede:
-
Segundo a extensão geográfica (ver mais detalhes abaixo em: Modelagem de rede de computadores segundo Tanenbaum):
-
SAN (Storage Area Network)
-
LAN (Local Area Network)
-
WLAN (Wireless Local Area Network)
-
PAN (Personal Area Network)
-
MAN (Metropolitan Area Network)
-
WMAN (Wireless Metropolitan Area Network), é uma rede sem fio de maior alcance em relação a WLAN
-
WAN (Wide Area Network)
-
WWAN (Wireless Wide Area Network)
-
RAN (Regional Area Network)
-
CAN (Campus Area Network)
-
-
Segundo a topologia:
-
Rede em anel (Ring)
-
Rede em barramento (BUS)
-
Rede em estrela (Star)
-
Rede em malha (Mesh)
-
Rede em ponto-a-ponto (ad-hoc)
-
-
Segundo o meio de transmissão:
Hardware de Rede
-
Elementos de Cabeamento:
-
Concentrador (hub)
-
Comutador (switch)
-
Roteador (router/gateway)
-
Porta de Ligação (gateway router)
-
Ponte (bridge)
O Modelo OSI
Interface de Rede
Um controlador de interface de rede (NIC) é um hardware de computador que fornece ao computador a capacidade de acessar a mídia de transmissão e tem a capacidade de processar informações de rede de baixo nível. Por exemplo, a NIC pode ter um conector para aceitar um cabo, ou uma antena para transmissão e recepção sem fio, e os circuitos associados.
O NIC responde ao tráfego dirigido a um endereço de rede para a NIC ou o computador como um todo. Em redes Ethernet, cada controlador de interface de rede possui um único endereço de Controle de Acesso de Mídia (MAC) - geralmente armazenado na memória permanente do controlador. Para evitar conflitos de endereço entre dispositivos de rede, o Instituto de Engenheiros Elétricos e Eletrônicos (IEEE) mantém e administra a unicidade de endereço MAC. O tamanho de um endereço MAC Ethernet é de seis octetos. Os três octetos mais importantes são reservados para identificar os fabricantes NIC. Esses fabricantes, usando apenas seus prefixos atribuídos, atribuem de forma exclusiva os três octetos menos significativos de cada interface Ethernet que eles produzem.
Repetidores e Hubs
Um repetidor é um dispositivo eletrônico que recebe um sinal de rede, o limpa de ruído desnecessário e o regenera. O sinal é retransmitido a um nível de potência mais alto, ou ao outro lado de uma obstrução, de modo que o sinal pode cobrir distâncias mais longas sem degradação. Na maioria das configurações de Ethernet de par trançado, são necessários repetidores para cabo que funciona com mais de 100 metros. Com as fibras ópticas, os repetidores podem estar a dezenas ou mesmo a centenas de quilômetros de distância.
Um repetidor com várias portas é conhecido como um hub Ethernet. Os repetidores trabalham na camada física do modelo OSI. Os repetidores requerem uma pequena quantidade de tempo para regenerar o sinal. Isso pode causar um atraso de propagação que afeta o desempenho da rede e pode afetar a função adequada. Como resultado, muitas arquiteturas de rede limitam o número de repetidores que podem ser usados em uma linha, por exemplo, a regra Ethernet 5-4-3.
Os hubs e repetidores nas LANs foram obsoletos principalmente por switches modernos.
Switches
Um switch de rede é um dispositivo que encaminha e filtra os datagramas da camada 2 OSI (quadros) entre as portas com base no endereço MAC de destino em cada quadro. [16] Uma opção é distinta de um hub na medida em que apenas encaminha os quadros para as portas físicas envolvidas na comunicação em vez de todas as portas conectadas. Pode ser pensado como uma ponte multi-porto. [17] Aprende a associar portas físicas a endereços MAC examinando os endereços de origem dos quadros recebidos. Se um destino desconhecido for segmentado, o switch transmite para todas as portas, mas a fonte. Os switches normalmente possuem inúmeras portas, facilitando uma topologia em estrela para dispositivos e comutadores adicionais em cascata.
Os switches de várias camadas são capazes de rotear com base no endereçamento da camada 3 ou níveis lógicos adicionais. O termo switch é freqüentemente usado vagamente para incluir dispositivos como roteadores e pontes, bem como dispositivos que podem distribuir tráfego com base na carga ou com base no conteúdo da aplicação (por exemplo, um identificador de URL da Web).
Roteadores
Um roteador é um dispositivo de interconexão que encaminha pacotes entre redes processando as informações de roteamento incluídas no pacote ou datagrama (informações de protocolo da Internet a partir da camada 3). As informações de roteamento geralmente são processadas em conjunto com a tabela de roteamento (ou tabela de encaminhamento). Um roteador usa sua tabela de roteamento para determinar onde encaminhar pacotes. Um destino em uma tabela de roteamento pode incluir uma interface "nula", também conhecida como a interface do "buraco negro", porque os dados podem entrar nela, no entanto, nenhum processamento adicional é feito para os ditos dados, isto é, os pacotes são descartados.
Meio físico
O meio mais utilizado hoje é o Ethernet. O padrão Ethernet vem subdividido em: Coax/10base2, UTP (Unshielded Twisted Pair - Par Trançado Não Blindado)/10BaseT e UTP/100baseT e Gigabit ethernet.
Também pode ser conectado por Fibra óptica, um fino filamento contínuo de vidro com uma cobertura de proteção que pode ser usada para conectar longas distâncias.
E ainda há as redes sem fios, que se subdividem em diversas tecnologias: Wi-fi, bluetooth, wimax e outras.
Modelagem de rede de computadores segundo Tanenbaum
Uma rede pode ser definida por seu tamanho, topologia, meio físico e protocolo utilizado.
-
PAN (Rede de área pessoal, tradução de Personal Area Network, é uma rede doméstica que liga recursos diversos ao longo de uma residência.) Uma rede de área pessoal (PAN) é uma rede de computadores usada para comunicação entre computador e diferentes dispositivos tecnológicos de informação perto de uma pessoa. Alguns exemplos de dispositivos que são usados em um PAN são computadores pessoais, impressoras, aparelhos de fax, telefones, PDAs, scanners e até mesmo consoles de videogames. Uma PAN pode incluir dispositivos com fio e sem fio. O alcance de uma PAN normalmente se estende a 10 metros. Uma PAN com fio geralmente é construído com conexões USB e FireWire enquanto tecnologias como Bluetooth e comunicação por infravermelho tipicamente formam um PAN sem fio.
-
LAN (Local Area Network, ou Rede Local). É uma rede onde seu tamanho se limita a apenas uma pequena região física. Uma rede de área local (LAN) é uma rede que conecta computadores e dispositivos em uma área geográfica limitada, como uma casa, escola, prédio de escritórios ou grupo de edifícios bem posicionado. Cada computador ou dispositivo na rede é um nó. LANs com fio são provavelmente baseadas em tecnologia Ethernet. Novos padrões como o ITU-T G.hn também fornecem uma maneira de criar uma LAN com fio usando a fiação existente, como cabos coaxiais, linhas telefônicas e linhas de energia. [26]
As características definidoras de uma LAN, em contraste com uma rede de área ampla (WAN), incluem maiores taxas de transferência de dados, alcance geográfico limitado e falta de dependência de linhas alugadas para fornecer conectividade. A Ethernet atual ou outras tecnologias LAN IEEE 802.3 funcionam a taxas de transferência de dados de até 100 Gbit / s, padronizadas pelo IEEE em 2010. [27] Atualmente, a Ethernet de 400 Gbit / s está sendo desenvolvida.
Uma LAN pode ser conectada a uma WAN usando um roteador.
-
VAN (Vertical Area Network, ou rede de vertical). É usualmente utilizada em redes prediais, vista a necessidade de uma distribuição vertical dos pontos de rede.
-
CAN (Campus Area Network, ou rede campus). Uma rede que abrange uma área mais ampla, onde pode-se conter vários prédios dentro de um espaço continuo ligados em rede. Esta segundo Tanenbaum em seu livro "Redes de computadores" é uma LAN, justamente porque esta área dita ampla, abrange 10 quarteirões ou aproximadamente 2.500m quadrados. Esta rede é pequena quando comparado a uma cidade.
-
MAN (Metropolitan Area Network, ou rede metropolitana). A MAN é uma rede onde temos por exemplo: Uma rede de farmácias, em uma cidade, onde todas acessam uma base de dados comum. As MAN oferecem altas taxas de transmissão, baixas taxas de erros, e geralmente os canais de comunicação pertencem a uma empresa de de telecomunicações que aluga o serviço ao mercado. As redes metropolitanas são padronizadas internacionalmente pela IEEE 802, e ANSI, e os padrões mais conhecidos para a construção de <AM são o DQDB (Distrubuted Queue Dual BUS) e o FDDI (Fiber Distributed Data Interface). Outro exemplo de rede metropolitana é o sistema utilizado nas TV's a cabo.
-
WAN (Wide Area Network, ou rede de longa distância). Uma WAN integra equipamentos em diversas localizações geográficas (hosts, computadores, routers/gateways, etc.), envolvendo diversos países e continentes como a Internet.
-
SAN (Storage Area Network, ou Rede de armazenamento). Uma SAN serve de conexão de dispositivos de armazenamento remoto de computador para os servidores de forma a que os dispositivos aparecem como locais ligados ao sistema operacional.
Topologia
Ver artigo principal: Topologia de rede
A topologia de rede é o canal no qual o meio de rede está conectado aos computadores e outros componentes de uma rede de computadores. Essencialmente, é a estrutura topológica da rede, e pode ser descrito física ou logicamente. Há várias formas nas quais se podem organizar a interligação entre cada um dos nós (computadores) da rede.[5] Existem duas categorias básicas de topologias de rede:
-
Topologia física
-
Topologia lógica
A topologia física é a verdadeira aparência ou layout da rede, enquanto que a lógica descreve o fluxo dos dados através da rede. A topologia física representa como as redes estão conectadas (layout físico) e o meio de conexão dos dispositivos de redes (nós ou nodos). A forma com que os cabos são conectados, e que genericamente chamamos de topologia da rede (física), influencia em diversos pontos considerados críticos, como a flexibilidade, velocidade e segurança.
A topologia lógica refere-se à maneira como os sinais agem sobre os meios de rede, ou a maneira como os dados são transmitidos através da rede a partir de um dispositivo para o outro sem ter em conta a interligação física dos dispositivos. Topologias lógicas são frequentemente associadas à Media Access Control, métodos e protocolos. Topologias lógicas são capazes de serem reconfiguradas dinamicamente por tipos especiais de equipamentos como roteadores e switches.
Topologia em Estrela
Ver artigo principal: Rede em estrela
Topologia de rede em estrela
Neste tipo de rede, todos os usuários comunicam-se com um nodo (nó) central, que tem o controle supervisor do sistema, chamado host. Por meio do host os usuários podem se comunicar entre si e com processadores remotos ou terminais. No segundo caso, o host funciona como um comutador de mensagens para passar dados entre eles.
O arranjo em estrela é a melhor escolha se o padrão de comunicação da rede for de um conjunto de estações secundárias que se comunicam com o nó central. As situações nas quais isso acontece são aquelas em que o nó central está restrito às funções de gerente das comunicações e a operações de diagnósticos.
O gerenciamento das comunicações por este nó central pode ser por chaveamento de pacotes ou de circuitos.
O nó central pode realizar outras funções além das de chaveamento e processamento normal. Por exemplo, pode compatibilizar a velocidade de comunicação entre o transmissor e o receptor. Se o protocolo dos dispositivos fonte e destino for diferente, o nó central pode atuar como um roteador, permitindo duas redes de fabricantes diferentes se comunicar.
No caso de ocorrer falha em uma estação ou na ligação com o nó central, apenas esta estação fica fora de operação.
Entretanto, se uma falha ocorrer no nó central, todo sistema pode ficar fora do ar. A solução deste problema seria a redundância, mas isto acarreta um aumento considerável de custos.
A expansão de uma rede desse tipo só pode ser feita até um certo limite, imposto pelo nó central: em termos de capacidade de chaveamento, número de circuitos concorrentes que podem ser gerenciados e números de nós que podem ser servidos.
O desempenho obtido numa rede em estrela depende da quantidade de tempo requerido pelo nó central para processar e encaminhar mensagens, e da carga de tráfego de conexão, ou seja, é limitado pela capacidade de processamento do nó central.
Esta configuração facilita o controle da rede e a maioria dos sistemas de computação com funções de comunicação possuem um software que implementa esta configuração.
Topologia em Barramento ou BUS
Ver artigo principal: Rede em bus
Topologia de rede em barramento - Simples
Topologia em barra comum é bastante semelhante ai conceito de arquitetura de barra em um sistema de computador, onde todas as estações (nós) se ligam ao mesmo meio de transmissão. Ao contrário das outras topologias, que são configurações ponto a ponto (isto é, cada enlace físico de transmissão conecta apenas dois dispositivos), a topologia em barra tem uma configuração multiponto.
Topologia em Anel
Ver artigo principal: Rede em anel
Topologia de rede em anel
A topologia em anel como o próprio nome diz tem um formato circular. A topologia mais famosa nesse tipo de rede de computadores é denominada Token Ring. Redes em anel são, teoricamente, capazes de transmitir e receber dados em qualquer direção. As configurações mais usuais, no entanto, são, unidirecionais, de forma a simplificar o projeto dos repetidores e tornar menos sofisticados os protocolos de comunicação que asseguram a entrega da mensagem ao destino corretamente e em sequência, pois sendo unidirecionais evitam o problema de roteamento. Os repetidores são em geral projetados de forma a transmitir e receber dados simultaneamente, diminuindo assim o retardo de transmissão. Quando uma mensagem é enviada por nó, ela entra no anel e circula até ser retirada pelo nó de destino, ou então até voltar ao nó de origem, dependendo do protocolo empregado. Além de maior simplicidade e do menor retardo introduzido, as redes onde a mensagem é retirada pelo nó de origem permitem mensagens de difusão (broadcast e multicast)
Protocolos de comunicação
Um protocolo de comunicação é um conjunto de regras para trocar informações através de uma rede. Em uma pilha de protocolos (veja também o modelo OSI), cada protocolo aproveita os serviços do protocolo abaixo. Um exemplo importante de uma pilha de protocolos é HTTP (o protocolo da World Wide Web) executando TCP sobre IP (os protocolos da Internet) em relação ao IEEE 802.11 (o protocolo Wi-Fi). Esta pilha é usada entre o roteador sem fio e o computador pessoal do usuário doméstico quando o usuário está navegando na web.
Embora o uso de camadas de protocolo seja hoje omnipresente no campo da rede de computadores, tem sido historicamente criticado por muitos pesquisadores [20] por dois motivos principais. Em primeiro lugar, o resumo da pilha de protocolos dessa maneira pode causar uma camada superior para duplicar a funcionalidade de uma camada inferior, sendo um exemplo excelente a recuperação de erro tanto por base de link quanto de fim a extremo. [21] Em segundo lugar, é comum que uma implementação de protocolo em uma camada possa exigir dados, informações de estado ou de endereçamento que estejam apenas presentes em outra camada, derrotando o ponto de separação das camadas em primeiro lugar. Por exemplo, o TCP usa o campo ECN no cabeçalho IPv4 como indicação de congestion; IP é um protocolo de camada de rede, enquanto o TCP é um protocolo de camada de transporte.
Os protocolos de comunicação possuem várias características. Eles podem estar orientados para conexão ou sem conexão, eles podem usar o modo de circuito ou a troca de pacotes, e eles podem usar o endereçamento hierárquico ou o endereçamento plano.
Existem muitos protocolos de comunicação, alguns dos quais estão descritos abaixo.
IEEE 802
O IEEE 802 é uma família de padrões IEEE que trata de redes de área local e redes de área metropolitana. O conjunto completo de protocolos IEEE 802 oferece um conjunto diversificado de recursos de rede. Os protocolos têm um esquema de endereçamento plano. Eles operam principalmente nos níveis 1 e 2 do modelo OSI.
Por exemplo, a ponte MAC (IEEE 802.1D) lida com o roteamento de pacotes Ethernet usando um protocolo Spanning Tree. O IEEE 802.1Q descreve VLANs e o IEEE 802.1X define um protocolo de controle de acesso à rede baseado em porta, que constitui a base para os mecanismos de autenticação usados nas VLANs (mas também é encontrado em WLANs) - é o que o usuário doméstico vê quando o o usuário deve inserir uma "chave de acesso sem fio".
Ethernet
A Ethernet, às vezes simplesmente chamada de LAN, é uma família de protocolos usados em redes LAN com fio, descritas por um conjunto de padrões, denominado IEEE 802.3, publicado pelo Instituto de Engenheiros Elétricos e Eletrônicos.
Wireless LAN
A LAN sem fio, também conhecida como WLAN ou WiFi, é provavelmente o membro mais conhecido da família de protocolos IEEE 802 para usuários domésticos hoje. É padronizado pelo IEEE 802.11 e compartilha muitas propriedades com Ethernet com fio.
Internet Protocol Suite
O Internet Protocol Suite, também chamado TCP / IP, é a base de todas as redes modernas. Oferece serviços de ligação e serviços orientados para conexão em uma rede intrinsecamente não confiável atravessada por transmissão de grama de dados no nível de protocolo de Internet (IP). No seu núcleo, o conjunto de protocolos define as especificações de endereçamento, identificação e roteamento para o Protocolo de Internet Versão 4 (IPv4) e para IPv6, a próxima geração do protocolo com uma capacidade de endereçamento muito ampliada.
SONET/SDH
A rede óptica síncrona (SONET) e a Hierarquia Digital Síncrona (SDH) são protocolos de multiplexação padronizados que transferem múltiplos fluxos de bits digitais em fibra óptica usando lasers. Eles foram originalmente projetados para transportar comunicações de modo de circuito de uma variedade de fontes diferentes, principalmente para suportar codificação de voz em tempo real, descompactada e comutada em circuito no formato PCM (Modulação de Código de Pulso). No entanto, devido à sua neutralidade de protocolo e recursos orientados para o transporte, a SONET / SDH também foi a escolha óbvia para o transporte de quadros de Modo de Transferência Assíncrona (ATM).
Asynchronous Transfer Mode
Modo de transferência assíncrona (ATM) é uma técnica de comutação para redes de telecomunicações. Ele usa multiplexação assíncrona de divisão de tempo e codifica dados em pequenas células de tamanho fixo. Isso difere de outros protocolos, como o Internet Protocol Suite ou Ethernet que usam pacotes de tamanho variável ou quadros. O ATM tem similaridade com o circuito e a rede comutada por pacotes. Isso faz com que seja uma boa opção para uma rede que deve lidar tanto com o tráfego de dados de alto débito tradicional quanto com o conteúdo em tempo real e de baixa latência, como voz e vídeo. ATM usa um modelo orientado a conexão em que um circuito virtual deve ser estabelecido entre dois pontos finais antes do início da troca de dados real.
Embora o papel do ATM esteja diminuindo em favor das redes da próxima geração, ele ainda desempenha um papel na última milha, que é a conexão entre um provedor de serviços de internet e o usuário doméstico.
Cellular standards
Existem vários padrões de celulares digitais diferentes, incluindo: Sistema Global para Comunicações Móveis (GSM), Serviço geral de rádio por pacotes (GPRS), cdmaOne, CDMA2000, Evolution-Data Optimized (EV-DO), taxas de dados aprimoradas para GSM Evolution ( EDGE), Universal Mobile Telecommunications System (UMTS), Digital Enhanced Cordless Telecommunications (DECT), Digital AMPS (IS-136 / TDMA) e Integrated Digital Enhanced Network (iDEN).
Escala Geográfica
Uma rede pode ser caracterizada pela sua capacidade física ou pelo seu propósito organizacional. O uso da rede, incluindo a autorização do usuário e os direitos de acesso, diferem em conformidade.
Rede de nanoescala
Uma rede de comunicação em nanoescala possui componentes-chave implementados a nanoescala, incluindo portadores de mensagens, e alavanca princípios físicos que diferem dos mecanismos de comunicação macro escala. A comunicação em nanoescala estende a comunicação a sensores e atuadores muito pequenos, como os encontrados em sistemas biológicos e também tende a operar em ambientes que seriam muito difíceis para a comunicação clássica
Rede de área pessoal.
Rede de área pessoal Uma rede de área pessoal (PAN) é uma rede de computadores usada para comunicação entre computador e diferentes dispositivos tecnológicos de informação perto de uma pessoa. Alguns exemplos de dispositivos que são usados em um PAN são computadores pessoais, impressoras, aparelhos de fax, telefones, PDAs, scanners e até mesmo consoles de videogames. Um PAN pode incluir dispositivos com fio e sem fio. O alcance de um PAN normalmente se estende a 10 metros.[6] Um PAN com fio geralmente é construído com conexões USB e FireWire enquanto tecnologias como Bluetooth e comunicação por infravermelho tipicamente formam um PAN sem fio.
Rede residencial
Uma rede de área residencial (HAN) é uma LAN residencial usada para comunicação entre dispositivos digitais tipicamente implantados em casa, geralmente um pequeno número de computadores e acessórios pessoais, como impressoras e dispositivos de computação móvel. Uma função importante é o compartilhamento de acesso à Internet, muitas vezes um serviço de banda larga através de um provedor de TV a cabo ou linha assinadora digital (DSL).
Rede de armazenamento
Uma rede de área de armazenamento (SAN) é uma rede dedicada que fornece acesso a um armazenamento consolidado de dados de nível de bloco. As SANs são usadas principalmente para criar dispositivos de armazenamento, como matrizes de disco, bibliotecas de fitas e jukeboxes ópticos, acessíveis aos servidores para que os dispositivos aparecem como dispositivos conectados localmente ao sistema operacional. Normalmente, uma SAN possui sua própria rede de dispositivos de armazenamento que geralmente não são acessíveis através da rede de área local por outros dispositivos. O custo e a complexidade das SANs caíram no início dos anos 2000 para níveis que permitiam maior adoção em ambientes empresariais e pequenas e médias empresas.
Rede de campus
Uma rede de área do campus (CAN) é constituída por uma interconexão de LANs dentro de uma área geográfica limitada. O equipamento de rede (switches, roteadores) e mídia de transmissão (fibra óptica, planta de cobre, cabeamento Cat5, etc.) são quase inteiramente de propriedade do inquilino / proprietário do campus (uma empresa, universidade, governo, etc.). Por exemplo, é provável que uma rede de campus universitário ligue uma variedade de edifícios do campus para se conectar a faculdades ou departamentos acadêmicos, a biblioteca e residências de estudantes.
Rede de espinha dorsal (Backbone)
Uma rede de espinha dorsal é parte de uma infraestrutura de rede informática que fornece um caminho para a troca de informações entre diferentes LANs ou sub-redes. Uma espinha dorsal pode unir redes diversas dentro do mesmo edifício, em diferentes edifícios, ou em uma ampla área.
Por exemplo, uma grande empresa pode implementar uma rede espinha dorsal para conectar departamentos que estão localizados em todo o mundo. O equipamento que une as redes departamentais constitui o espinha dorlsa da rede. Ao projetar uma rede de espinha dorsal, o desempenho da rede e o congestionamento da rede são fatores críticos para levar em consideração. Normalmente, a capacidade da rede backbone é maior que a das redes individuais conectadas a ele.
Outro exemplo de uma rede espinha dorlsa é o espinha dorsal da Internet, que é o conjunto de redes de área ampla (WANs) e roteadores principais que vinculam todas as redes conectadas à Internet.
Rede metropolitana
Uma rede de área metropolitana (MAN) é uma rede de computadores de grande porte que normalmente abrange uma cidade ou um campus grande.
Wireless
Principais padrões
Os principais padrões na família IEEE 802.11 são:
IEEE 802.11: Padrão Wi-Fi para frequência 2.4 GHz com capacidade teórica de 2 Mbps.
IEEE 802.11a: Padrão Wi-Fi para frequência 5 GHz com capacidade teórica de 54 Mbps.[1]
IEEE 802.11b: Padrão Wi-Fi para frequência 2,4 GHz com capacidade teórica de 11 Mbps. Este padrão utiliza DSSS (Direct Sequency Spread Spectrum – Sequência Direta de Espalhamento de Espectro) para diminuição de interferência.[1]
IEEE 802.11g: Padrão Wi-Fi para frequência 2,4 GHz com capacidade teórica de 54 Mbps.[1]
IEEE 802.11n: Padrão Wi-Fi para frequência 2,4 GHz e/ou 5 GHz com capacidade de 150 a 600 Mbps. Esse padrão utiliza como método de transmissão MIMO-OFDM.[1]
Wi-Fi Protected Access (WPA e WPA2): padrão de segurança instituído para substituir padrão WEP (Wired Equivalent Privacy) que possui falhas graves de segurança, possibilitando que um hacker possa quebrar a chave de criptografia após monitorar poucos minutos de comunicação.[2]
A família 802.11 inclui técnicas de modulação no ar que usam o mesmo protocolo básico. Os mais populares são os definidos pelos protocolos 802.11b e 802.11g e são emendas ao padrão original. O 802.11-1997 foi o primeiro padrão de rede sem fio, mas o 802.11b foi o primeiro largamente aceitado, seguido do 802.11g e 802.11n. A segurança foi, no início, propositalmente fraca devido a requisitos de exportação de alguns governos, e mais tarde foi melhorada através da emenda 802.11i após mudanças governamentais e legislativas. O 802.11n é uma nova tecnologia multi-straming de modulação que está ainda em desenvolvimento, mas produtos baseados em versões proprietárias do pré-rascunho já são vendidas. Outros padrões na família (c-f, h, j) são emendas de serviço e extensões ou correções às especificações anteriores.[1]
802.11b e 802.11g usam a banda 2.4GHz ISM, operando nos Estados Unidos sobre a Part 15 do US Federal Communications Commission Rules and Regulations. Por causa desta escolha de frequência de banda, equipamentos 802.11b e g podem, ocasionalmente, sofrer interferências de fornos microondas e telefones sem fio. Dispositivos Bluetooth, enquanto operando na mesma banda, em teoria não interferem no 802.11b/g por que usam um método chamado frequency hopping spread spectrum signaling (FHSS) enquanto o 802.11b/g usa um método chamado direct sequence spread spectrum signaling (DSSS). O 802.11a usa a banda 5GHz U-NII, que oferece 8 canais não sobrepostos ao invés dos 3 oferecidos na frequência de banda 2.4GHz ISM.[1]
O segmento do espectro da frequência de rádio utilizado varia entre os países. Nos EUA, dispositivos 802.11a e 802.11g podem operar sem licença, como explicado na Parte 15 do FCC Rules and Regulations. Frequências usadas por canais um a seis (802.11b) caem na banda de rádio amador de 2.4GHz. Operadores licenciados de rádio amador podem operar dispositivos 802.11b/g sob a Parte 97 do FCC Rules and Regulatins, permitindo uma saída maior de energia mas não conteúdo comercial ou encriptação.[1]
Em 2015, a tecnologia 802.11ac deve começar a ser utilizada. A tecnologia aumenta a velocidade para 1.300 Mpbs e será, em média, cinco vezes mais rápida do que a atua. Além disso, o 'Wi-Fi AC' economizará a bateria dos dispositivos, já que o tempo de download será menor. [3].

IEEE 802.11ac
IEEE 802.11ac ou Padrão 802.11ac é a nova geração da tecnologia de transmissão em redes locais sem fio
(WI-FI WLAN) pertencentes a família 802.11 (desenvolvida pela organização IEEE standards association) de alto desempenho, na frequência de 5GHz.
Este padrão foi desenvolvido entre 2011 e 2013, com previsão de lançamento somente para o início de 2020. O Padrão Trabalha com multiestações de transferência sem-fio de na escala de Gbit/s em link único de transferência, graças ao conceito de extensão de interface, já implementado no modelo 802.11n.
A tecnologia MIMO, dividida em SU-MIMO e MU-MIMO, é um desdobramento de vários avanços feitos com o objetivo de aumentar a velocidade de redes sem fio, sejam domésticas, corporativas ou de celulares. Em um mundo cada vez mais conectado, o sistema é fundamental para smartphones, tablets, notebooks e até mesmo eletrodomésticos que acessam a Internet. Responsável por alcançar taxas de transmissão mais altas, a MIMO oferece mais velocidade para cada aparelho conectado, por exemplo, ajudando a melhorar o modo de transmissão do sinal. Ficou curioso sobre a tecnologia? Confira abaixo as principais funções, classificações e vantagens do sistema que já está presente em roteadores mais avançados e em smartphones tops de linha como iPhone 6S e Galaxy S7.
MIMO é a sigla em inglês para Multiple Input Multiple Output que, em uma tradução literal, significa “Múltiplas Entradas Múltiplas Saídas”. Trata-se de um sistema que visa alcançar maiores taxas de transmissão em redes sem fios. A tecnologia usa várias antenas para transmitir o sinal e os dados em uma rede. Assim, quanto mais antenas, mais rápida e eficiente será a transmissão e recepção dos dados aos diversos aparelhos conectados. Daí o nome “múltiplas entradas e saídas”. Este sistema é o sucessor do IEEE 802.11n e foi nomeado de 802.11ac, formato que recebeu atualizações em julho. Além de suas melhorias na velocidade de transmissão e recepção, o padrão gasta menos energia e tem uma segurança mais aprimorada.
Principais funções
O sistema MIMO possui três funções distintas. A STTD, a SM e a transmissão colaborativa. STTD é a sigla para Space Time Transmit Diversity. Neste modo, todas as antenas transmitem exatamente o mesmo sinal. Isso serve para aumentar a potência da rede. Porém, a velocidade continua a mesma.
Já na função SM (Spatial Multiplexing), cada antena transmite dados diferentes. Isso aumenta a taxa de transferência da rede, ou seja, a sua velocidade. Porém, o alcance continua o mesmo. Esta técnica também é conhecida como OFDM-MIMO e é usada em roteadores no padrão 802.11n e as redes celulares mais atuais.
Por fim, na transmissão colaborativa, mais de um roteador pode ser combinado para ter um dos outros dois sistemas, unindo o melhor dos dois mundos. Este modo, porém, é o mais incomum.
Classificações
O sistema MIMO pode ser classificado no formato: "axb:c". A letra A indica o número de antenas de transmissão, a letra B o número de antenas de recepção e a letra C o número de fluxos espaciais. Vamos aos
exemplos:
Um sistema MIMO-OFDM 2x2 indica que há duas antenas transmissoras e duas antenas receptoras atuando no modo OFDM (ou SM), ou seja, cada uma transmite dados diferentes, aumentando a velocidade. Assim, ele poderia ser descrito como 2x2:2. Em um sistema 3x3:3, haveriam três antenas de transmissão, três de recepção em três fluxos espaciais, triplicando a velocidade.
Vantagens do sistema MIMO
Em uma rede wireless tradicional, o roteador pode dar atenção apenas a um dispositivo por vez. Então, imagine que você tenha um notebook, um tablet e um smartphone ligados a uma mesma rede Wi-Fi. O notebook está em uma partida online, o tablet está transmitindo um filme pelo Netflix e o smartphone fazendo streaming pelo YouTube. O roteador primeiro transmite e recebe alguns dados da partida online, depois para de dar atenção à partida e transmite alguns pacotes de dados para o Netflix e depois para o YouTube. Embora o usuário não perceba essas paradas, é assim que os roteadores atuam.
Por isso, para se ter um melhor desempenho em partidas onlines, é recomendável desligar tudo aquilo que possa consumir banda, tais como streaming de vídeos ou de músicas. E é por isso que quando há muitos dispositivos ligados na rede ao mesmo tempo os vídeos travam, por exemplo.
Em um sistema MIMO de três antenas, cada uma das antenas transmite um tipo diferente de dados. Assim, voltando para a situação apresentada, uma antena ficaria dedicada para o notebook, a segunda para o smartphone e a terceira para o tablet, não havendo diminuição de velocidade.
A tecnologia MIMO ainda pode ser dividida em SU-MIMO e MU-MIMO, onde SU significa Single User (usuário único) e MU significa Multiple User (usuários múltiplos). A tecnologia MU-MIMO é a que pode transmitir diferentes tipos de dados simultaneamente.
Onde atua
No caso da tecnologia MU-MIMO, mais avançada, é possível encontrá-la em ação nos mais recentes e avançados roteadores, como o Asus RT-AC87U e o TP-Link Archer C2600. No Brasil, já é possível encontrar a tecnologia no DIR-890L, da D-Link. Alguns smartphones e tablets tops de linha também contam com tal sistema, tais como o iPhone 6S e o Galaxy S7.
Veja como Configurar e calcular uma rede Wi-Fi UniFi
É importante lembrar que um dos pontos mais importantes em uma rede Wi-Fi Corporativa, é a qualidade de sinal, onde cada local de um Access Point deve ser planejado. Uma rede Wi-Fi corporativa precisa ter a garantia de estabilidade e velocidade, desde que projetada corretamente e para isto, é necessário aprender a calcular uma célula Wireless, que depende de vários fatores, tais como, Perfil de usuário, velocidade a ser entregue a cada usuário, qualidade do sinal recebido, modulação referente ao sinal recebido, índices de reflexão, taxas de velocidade real (Ex. TCP), nível de retransmissão, entre outros pontos importantes.
O primeiro passo para um cálculo correto é entender a parte física (sinais), em seguida, atribuir o número de APs que atenderão o projeto, então, vamos ao cálculo:
Após o sinal ser identificado (em porcentagem) podemos calcular a capacidade daquela célula. Em nosso humilde exemplo, utilizaremos um AP com 3 usuários, um deles com 99% de sinal, outros com 50% de sinal e o último com 25% de sinal em relação a qualidade, ou seja, temos um cenário variado justamente para criar uma simulação próxima da realidade. O SNR de cada usuário será diferente:
Usuário 1 = 99% = SNR de 33 dBm
Usuário 2 = 50% = SNR de 26 dBm
Usuário 3 = 25% = SNR de 16 dBm
Neste exemplo, criaremos uma situação delicada em relação a velocidade, pois termos estações que atingirão baixas taxas de transmissão de velocidades.
Equação de % Sinal UniFi
Apresentando Considerações Físicas:
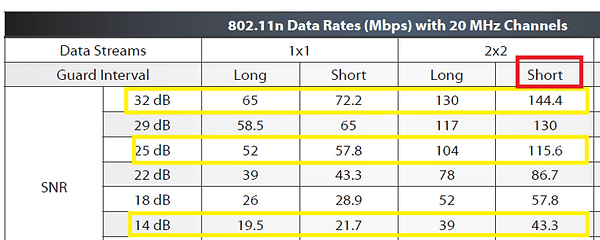
Largura de Canal = 20 MHz
MIMO = 2×2
ENTELCO Tabela de Velocidades UniFi
Intervalo de Guarda = Curto
Calculo de Velocidade Nominal de cada usuário
Usuário 1 = 144,4 Mbps > Throughput TCP = 72,2 Mbps
Usuário 2 = 115,6 Mbps > Throughput TCP = 57,85 Mbps
Usuário 3 = 43,3 Mbps > Throughput TCP = 21,65 Mbps
Avaliando as Considerações de Tráfego:
Em relação a velocidade nominal podemos considerar 50% para a velocidade “real” em tráfego TCP, ou seja, dividimos a velocidade por 2.
Para calcularmos a célula toda, dividiremos um total de 100%, por 3, que é o número de usuários nesta situação, portanto, teremos 33,33% para cada usuário.
33.33% * 72,2 Mbps = 24,067 Mbps
33.33% * 57,8 Mbps = 19,267 Mbps
33.33% * 21,65 Mbps = 7,217 Mbps
Velocidade Total Agregada
7,217 + 19,267 + 24,067 = 50,551 Mbps
Neste caso foram somadas as velocidades que cada usuário conseguirá atingir com as suas qualidades em percentuais equivalentes.
A velocidade total deste AP será de até 50,5 Mbps (“Real”), devido a variação de sinal e velocidade de cada usuário conectado a esta célula. Mesmo que um equipamento traga as informações comerciais que ele opere até 300 ou 450 Mbps, temos uma série de fatores que precisam ser estudados para atingirmos tais velocidades. Vale lembrar que é um cenário definido por exemplos, mas a nossa realidade é muitíssimo parecida com este exemplo. No final das contas, temos uma limitação de velocidade devido ao sinal ser baixo em alguns casos, assim como do usuário 3 que podemos classificar como um sinal péssimo. Temos muitos pontos que devem ser avaliados em uma rede, então, não basta ter sinal forte, ou ter uma latência (ping) baixa.
Vantagens
O protocolo 802.11 ac, ou a nova geração da tecnologia de transmissão em redes locais sem fio (WI-FI WLAN) logo fará parte da maioria das empresas. Uma das características deste protocolo é a transmissão de dados em 5 GHz. Em um ambiente limpo, a velocidade mais comum é de 2.4 GHz. Outro grande benefício do padrão é o alcance do sinal que pode chegar a realizar transmissões para computadores ou outros dispositivos que estejam a 200 metros de distância. Tudo isso evidencia que, além da melhoria da cobertura e da velocidade, o padrão 802.11ac tornou a distribuição dos dados mais inteligentes. Isso porque, neste padrão, as ondas não são propagadas de forma uniforme em todas as direções, como nos padrões passados. No ‘ac’ os roteadores reforçam o sinal para as áreas as quais têm dispositivos conectados. Essa tecnologia é chamada de Beamforming. Com esse recurso, os problemas com os pontos cegos, ou seja, os locais nos quais o sinal não chegava, são parcialmente resolvidos.
O protocolo 802.11 ac se apresenta como uma boa alternativa, com muitas vantagens, quando comparado a versões anteriores de protocolo. Abaixo, sugerimos alguns motivos para a utilização do protocolo. Confira:
1- Agilidade
Como todos nós sabemos, tempo é dinheiro, ainda mais no mundo empresarial. Com o protocolo 802.11ac há inúmeras melhorias na velocidade de transmissão de dados, lembrando que é necessário um hardware compatível em ambos os lados da conexão sem fio.
2- Transmissão de longo alcance
As tecnologias encontradas em 802.11ac permitem que os dispositivos finais se conectem de forma mais confiável em intervalos mais longos. Ou seja, a distância dentro do ambiente empresarial, ou até mesmo doméstico, não será problema com este protocolo. O 11ac pode estender a gama de APs nas proximidades, possivelmente, cobrindo a área ao ar livre onde outras tecnologias 802.11ac não alcançam.
3- Compatibilidade com versões anteriores
Neste sentido vale ressaltar que o protocolo 802.11ac é totalmente compatível e pode trabalhar lado a lado com APs mais velhos, sem medo de interferir em tecnologias mais antigas. Então, se você deseja executar uma atualização sem interrupção, misturando 802.11ac APs com APs da geração anterior, tudo bem. Basta ter em mente que os APs mais recentes podem acabar sendo os APs mais fáceis para a conexão.
4- Preço semelhante
Alguns fornecedores de Wi-Fi estão vendendo pontos de acesso 802.11ac com capacidade pelo mesmo preço - ou mais barato - do que hardware 802.11n. Vale pesquisar se tiver a intenção de instalar ou mesmo atualizar a rede sem fio da empresa.
5- Multiusuário
O protocolo 802.11ac é conhecido como multiusuário de entrada múltipla/saída múltipla (MIMO multiusuário). O que isso significa? Essencialmente, o ponto de acesso sem fio pode enviar vários quadros para vários clientes usando as mesmas frequências. Ele faz isso através da utilização de vários arranjos de antenas incorporadas para uma 802.11ac.
6- Múltiplos canais
Com o protocolo 802.11ac é possível ter várias opções de ligação de canal. Com isso, combinar múltiplos canais em conjunto para transmitir maiores larguras de banda é um dos benefícios que este protocolo proporciona. Enquanto o 802.11n oferece 40 MHz a ligação de canais, o 802.11ac permite a 80 MHz e Wave 2 permite 160 MHz canal de ligação.
7- 256 – QAM
O protocolo 802.11ac oferece mais dados em cada onda. Isso signifca que teoricamente o usuário pode alcançar uma vantagem de 33% a mais na taxa de transferência. Para isso, o dispositivo sem fio precisa estar em uma posição perto da AP e com pouca interferência.
8- Planeje a mudança
Apesar do protocolo 802.11ac oferecer muitos benefícios, é preciso planejar as mudanças. Isso porque é preciso saber se a rede comporta as adaptações necessárias com especialistas na área de Tecnologia da Informação. O motivo é simples: com todos os benefícios que este protocolo oferece, as empresas irão optar por ele. E, neste caso, é preciso ver se a rede comporta essa demanda, caso contrário, será um investimento não aproveitado de início porque primeiramente deverá ser feita a troca da rede.
9- Vale a pena?
O equipamentos “ac” estão ficando cada vez mais comuns, e atualmente é possível adquirir pontos de acesso 802.11ac por um preço semelhante aos pontos de acesso 802.11n.
10- Ganhos
Com a utilização do protocolo 802.11ac, a empresa terá muitos ganhos e o retorno do investimento é rápido. Os ganhos de produtividade podem ser relevantes em locais de trabalho em que a demanda por acessos sem fio seja estratégica. Além disso, vários dispositivos já estão saindo de fábrica compatíveis com o protocolo 802.11ac. Como se pode perceber, o uso do protocolo 802.11ac logo será comum nas empresas. Tudo será uma questão de modernização, afinal, não é uma tecnologia do futuro, mas do presente, e vai demorar mais para se tornar obsoleto, enquanto o padrão “n” já pode ser considerado ultrapassado.
https://blogbrasil.comstor.com/10-motivos-para-utilizar-o-protocolo-80211ac'

http://www.networkcomputing.com/wireless-infrastructure/7-reasons-you-need-80211ac/142240611 http://www.hardware.com.br/artigos/entendendo-wifi-802.11-ac/ https://www.palpitedigital.com/wi-fi-802-11-abgnacad-afinal-que-significa-isso/ http://teltecsolutions.com.br/mundo/2015-sera-o-ano-da-802-11ac-entenda-por-que/
D N S - Domain Name System
O Sistema de Nomes de Domínio,[1][2][3] mais conhecido pela nomenclatura em Inglês Domain Name System(DNS), é um sistema hierárquico e distribuído de gestão de nomes para computadores, serviços ou qualquer máquina conectada à Internet ou a uma rede privada. Faz a associação entre várias informações atribuídas a nomes de domínios e cada entidade participante. A sua utilização mais convencional associa nomes de domínios mais facilmente memorizáveis a endereços IP numéricos, necessários à localização e identificação de serviços e dispositivos, processo esse denominado por: resolução de nome. Em virtude do banco de dados de DNS ser distribuído, o seu tamanho é ilimitado e o desempenho não se degrada substancialmente quando se adicionam mais servidores. Por padrão, o DNS usa o protocolo User Datagram Protocol (UDP) na porta 53 para servir as solicitações e as requisições.[4]
O DNS apresenta uma arquitetura cliente/servidor, podendo envolver vários servidores DNS na resposta a uma consulta. O servidor DNS resolve nomes para os endereços IP e de endereços IP para os nomes respectivos, permitindo a localização de hosts num determinado domínio.
Num sistema livre, o serviço é normalmente implementado pelo software BIND. Este serviço geralmente encontra-se localizado no servidor DNS primário. O servidor DNS secundário é uma espécie de cópia de segurança do servidor DNS primário. Assim, é uma parte necessária para quem quer usar a internet de uma forma mais fácil, evita que hackers roubem dados pessoais.[5]
Existem centenas de servidores-raiz DNS (root servers) no mundo todo, agrupados em 13 zonas DNS raiz,[6] das quais sem elas a Internet não funcionaria. Destes, dez estão localizados nos Estados Unidos da América, dois na Europa e um na Ásia. Para aumentar a base instalada destes servidores foram criadas réplicas localizadas por todo o mundo, inclusive no Brasil desde 2003.
História
A implementação do DNS-Berkeley, foi desenvolvida originalmente para o sistema operacional BSD UNIX 4.3. A implementação do Servidor de DNS Microsoft se tornou parte do sistema operacional Windows NT na versão Server 4.0. O DNS passou a ser o serviço de resolução de nomes padrão a partir do Windows 2000 Server como a maioria das implementações de DNS teve suas raízes nas RFCs 882 e 883, e foi atualizado nas RFCs 1034 e 1035.
Visão geral
Um recurso da internet, por exemplo um site da Web, pode ser identificado de duas maneiras: pelo seu nome de domínio[7], por exemplo, “www.wikipedia.org” ou pelo endereço de IP[8] dos equipamentos que o hospedam (por exemplo, 208.80.152.130 é o IP associado ao domínio www.wikipedia.org[9]). Endereços IP são usados pela camada de rede para determinar a localização física e virtual do equipamento. Nomes de domínio, porém, são mais mnemônicos para o usuário e empresas. É então necessário um mecanismo para resolver um nome de domínio em um endereço IP. Esta é a principal função do DNS.
Ocasionalmente, presume-se que o DNS serve apenas o objetivo de mapear nomes de hosts da Internet a dados e mapear endereços para nomes de host. Porém, o DNS pode armazenar uma grande variedade de tipo de dados, para praticamente qualquer finalidade.[10]
Hierarquia
Devido ao tamanho da Internet, armazenar todos os pares domínio - endereço IP em um único servidor DNS seria inviável por questões de escalabilidade, que incluem:
-
Disponibilidade: se o único servidor de DNS falhasse, o serviço se tornaria indisponível para o mundo inteiro;
-
Volume de tráfego: o servidor deveria tratar os pedidos DNS do planeta inteiro;
-
Distância: grande parte dos usuários estaria muito distante do servidor, onde quer que ele fosse instalado, gerando grandes atrasos para resolver pedidos DNS;
-
Manutenção do banco de dados: o banco de dados deveria armazenar uma quantidade de dados enorme e teria que ser atualizado com uma frequência muito alta (assim que um novo domínio fosse associado a um endereço IP).
A solução encontrada foi usar uma base de dados distribuída e hierárquica. Os servidores DNS se dividem nas seguintes categorias:
-
Servidores-raiz;
-
Servidores de domínio de topo;
-
Servidores com autoridade.
Servidores-raiz
Ver artigo principal: Servidor-raiz
No topo da hierarquia estão os 13 servidores raiz. Um servidor-raiz (root name server) é um servidor de nome para a zona raiz do DNS (Domain Name System). A sua função é responder diretamente às requisições de registros da zona raiz e responder a outras requisições retornando uma lista dos servidores de nome designados para o domínio de topo apropriado. Os servidores raiz são parte crucial da Internet porque são o primeiro passo em resolver nomes para endereços IP, esses últimos usados para comunicação entre hosts.
Servidores de domínio de topo (top-level domain)
Cada domínio é formado por nomes separados por pontos. O nome mais à direita é chamado de domínio de topo. Exemplos de domínios de topo são .com, .org, .net, .edu, .inf, .gov.
Cada servidor de domínio de topo conhece os endereços dos servidores autoritativos que pertencem àquele domínio de topo, ou o endereço de algum servidor DNS intermediário que conhece um servidor autoritativo.
Há também terminações orientadas a países, chamadas de Código de País para Domínios de Topo/Primeiro Nível (Country Code Top Level Domains). Por exemplo: .br para o Brasil, .ar para a Argentina, .fr para a França e assim por diante. Há também combinações, como .com.br e .blog.br.[11]
Servidores com autoridade
O servidor com autoridade de um domínio possui os registros originais que associam aquele domínio a seu endereço de IP. Toda vez que um domínio adquire um novo endereço, essas informações devem ser adicionadas a pelo menos dois servidores autoritativos[12]. Um deles será o servidor autoritativo principal e o outro, o secundário. Isso é feito para minimizar o risco de, em caso de erros em um servidor DNS, perder todas as informações originais do endereço daquele domínio.
Métodos de resolução: iterativo e recursivo
Com as três classes de servidores DNS, já é possível resolver qualquer requisição DNS. Basta fazer uma requisição a um servidor raiz, e esse retornará o endereço do servidor de topo responsável. Então repete-se a requisição para o servidor de topo, que retornará o endereço do servidor autoritativo ou algum intermediário. Repete-se a requisição aos servidores intermediários (se houver) até obter o endereço do servidor autoritativo, que finalmente retornará o endereço IP do domínio desejado.
Repare que essa solução não resolve um dos problemas de escalabilidade completamente: os servidores raiz tem que ser acessados uma vez para cada requisição que for feita em toda a internet. Esses servidores também podem estar muito longe do cliente que faz a consulta. Além disso, para resolver cada requisição, são precisas várias consultas, uma para cada servidor na hierarquia entre o raiz e o autoritativo.
Esta forma de resolver consultas é chamada de iterativa ou não-recursiva: cada servidor retorna ao cliente (ou ao servidor local requisitante, como explicado adiante) o endereço do próximo servidor no caminho para o autoritativo, e o cliente ou servidor local fica encarregado de fazer as próximas requisições.
Há também o método recursivo: o servidor pode se responsabilizar por fazer a requisição ao próximo servidor, que fará a requisição ao próximo, até chegar ao autoritativo, que retornará o endereço desejado, e esse endereço será retornado para cada servidor no caminho até chegar ao cliente. Esse método faz com que o cliente realize apenas uma consulta e receba diretamente o endereço desejado, porém aumenta a carga dos servidores no caminho. Por isso, servidores podem se recusar a resolver requisições recursivas.
Melhorias de performance
Dois recursos são usados em conjunto para reduzir a quantidade de requisições que os servidores raiz devem tratar e a quantidade de requisições feitas para resolver cada consulta: cache e servidor local.
Cache
Toda vez que um servidor retorna o resultado de uma requisição para a qual ele não é autoridade (método de resolução recursivo), ele armazena temporariamente aquele registro. Se, dentro do tempo de vida do registro (TTL, Time to Live), alguma requisição igual for feita, o servidor DNS pode retornar o resultado sem a necessidade de uma nova consulta. Note que isso pode provocar inconsistência, já que se um domínio mudar de endereço durante o tempo de vida do cache, o registro estará desatualizado. Apenas o servidor autoritativo tem a garantia de ter a informação correta. É possível exigir, na mensagem de requisição DNS, que a resposta seja dada pelo servidor autoritativo.
Servidor local
Esse tipo de servidor não pertence à hierarquia DNS, mas é fundamental para o seu bom funcionamento. Em vez de fazer requisições a um servidor raiz, cada cliente faz sua requisição a um servidor local, que geralmente localiza-se fisicamente muito próximo do cliente, por exemplo um servidor proxy. Este se encarrega de resolver a requisição. Com o uso de cache, o servidor local pode ter a resposta pronta, ou ao menos conhecer algum servidor mais próximo ao autoritativo que o raiz (por exemplo, o servidor de topo), reduzindo a carga dos servidores raiz.
DNS reverso (reverse lookup)
Normalmente o DNS atua resolvendo o nome do domínio de um host qualquer para seu endereço IP correspondente. O DNS Reverso resolve o endereço IP, procurando o nome de domínio associado ao host. Ou seja, quando temos disponível o endereço IP de um host e não sabemos o endereço do domínio (nome dado à máquina ou outro equipamento que acesse uma rede), tentamos resolver o endereço IP através do DNS reverso que procura qual nome de domínio está associado àquele endereço. Os servidores que utilizam o DNS Reverso conseguem verificar a autenticidade de endereços, verificando se o endereço IP atual corresponde ao endereço IP informado pelo servidor DNS. Isto evita que alguém utilize um domínio que não lhe pertence para enviar spam, por exemplo.
PROXI SERVER
Em redes de computadores, um proxy (em português 'procurador', 'representante') é um servidor(um sistema de computador ou uma aplicação) que age como um intermediário para requisições de clientes solicitando recursos de outros servidores. Um cliente conecta-se ao servidor proxy, solicitando algum serviço, como um arquivo, conexão, página web ou outros recursos disponíveis de um servidor diferente, e o proxy avalia a solicitação como um meio de simplificar e controlar sua complexidade. Os proxies foram inventados para adicionar estrutura e encapsulamento aos sistemas distribuídos. Esses servidores têm uma série de usos, como filtrar conteúdo, providenciar anonimato, entre outros. Hoje, a maioria dos proxies é proxy web, facilitando o acesso ao conteúdo na World Wide Web e fornecendo anonimato.
Um servidor proxy pode, opcionalmente, alterar a requisição do cliente ou a resposta do servidor e, algumas vezes, pode disponibilizar este recurso mesmo sem se conectar ao servidor especificado. Pode também atuar como um servidor que armazena dados em forma de cache em redes de computadores. São instalados em máquinas com ligações tipicamente superiores às dos clientes e com poder de armazenamento elevado.
Um proxy de cache HTTP ou, em inglês, caching proxy, permite por exemplo que o cliente requisite um documento na World Wide Web e o proxy procura pelo documento na sua caixa (cache).
Se encontrado, a requisição é atendida e o documento é retornado imediatamente. Caso contrário, o proxy busca o documento no servidor remoto, entrega-o ao cliente e salva uma cópia em seu cache. Isto permite uma diminuição na latência, já que o servidor proxy, e não o servidor original, é requisitado, proporcionando ainda uma redução do uso da largura de banda.
Surgimento
O servidor proxy surgiu da necessidade de conectar uma rede local (ou LAN) à Internet através de um computador da rede que compartilha a sua conexão com as demais máquinas. Ou seja, se considerarmos que a rede local é uma rede "interna" e a Interweb é uma rede "externa", podemos dizer que o proxy é aquele que permite que outras máquinas tenham acesso externo.
Geralmente, as máquinas da rede interna não possuem endereços válidos na Internet e, portanto, não têm uma conexão direta com a mesma. Assim, toda a solicitação de conexão de uma máquina da rede local para uma máquina da Internet é direcionada ao proxy; este, por sua vez, realiza o contato com máquina desejada, repassando a resposta da solicitação para a máquina da rede local. Por este motivo, é utilizado o termo proxy para este tipo de serviço, que, em Informática, é geralmente traduzido como intermediário. Outra acepção aceita é procurador (também fora do contexto da Informática).
Usos de servidores proxy
Monitoramento e filtragem, Software de controle de conteúdo
Um servidor proxy web de filtro de conteúdo fornece controle administrativo sobre o conteúdo que pode trafegar em ambas as direções pelo proxy. É comumente utilizado em organizações comerciais e não-comerciais (especialmente escolas) para garantir que o uso da Internet está de acordo com a política de uso aceitável.
Um proxy de filtragem de conteúdo frequentemente suportará autenticação de usuário, para controlar o acesso a web. Ele normalmente também produz registros com detalhes das URLs acessadas por usuários específicos ou para monitorar estatísticas de uso da largura de banda.
Melhorar o desempenho
Um servidor de proxy de cache acelera as requisições de serviços recuperando o conteúdo salvo de uma requisição anterior realizada por qualquer cliente da rede local. Proxies de cache armazenam cópias locais de recursos requisitados com frequência, permitindo que grandes organizações reduzam significativamente seus custos e montantes de utilização de largura de banda, enquanto aumentam significativamente o desempenho. A maioria dos PSIs (Provedores de Serviço de Internet) e grandes empresas possuem um proxy de cache. Os proxies de cache foram os primeiros tipos de servidores proxy. Proxies web são normalmente usados para armazenar páginas web de um servidor web. Proxies de cache implementados de maneira inadequada podem causar problemas, como uma incapacidade de utilizar autenticação de usuário.
Implementações de servidores proxy
Servidores proxy web
Uma aplicação proxy popular é o proxy de armazenamento local (ou cache) web, em inglês caching web proxy, um proxy web usado para armazenar e atualizar (conforme pré-programado). Este provê um armazenamento local de páginas da Internet e arquivos disponíveis em servidores remotos da Internet assim como sua constante atualização, permitindo aos clientes de uma rede local (LAN) acessá-los mais rapidamente e de forma viável sem a necessidade de acesso externo.
Quando este recebe uma requisição para acesso a um recurso da Internet (a ser especificado por uma URL), um proxy que usa cache procura resultados da URL em primeira instância no armazenamento local. Se o recurso for encontrado, este é consentido imediatamente. Senão, carrega o recurso do servidor remoto, retornando-o ao solicitante que armazena uma cópia deste na sua unidade de armazenamento local. O cache usa normalmente um algoritmo de expiração para a remoção de documentos e arquivos de acordo com a sua idade, tamanho e histórico de acesso (previamente programado). Dois algoritmos simples são o Least Recently Used (LRU) e o Least Frequently Used (LFU). O LRU remove os documentos que passaram mais tempo sem serem usados, enquanto o LFU remove documentos frequentemente menos usados.
Uniform Resource Locator (URL), é um termo técnico (e anglicismo de tecnologia da informação) que foi traduzido para a língua portuguesa como "localizador uniforme de recursos". Um URL se refere ao endereço de rede no qual se encontra algum recurso informático, como por exemplo um arquivo de computador ou um dispositivo periférico (impressora, equipamento multifuncional, unidade de rede etc.). Essa rede pode ser a Internet, uma rede corporativa (como uma intranet) etc. Nas redes TCP/IP, um URL completo possui a seguinte estrutura: esquema ou protocolo://domínio:porta/caminho/recurso?query_string#fragmento
Exemplo: http://www.w3.org/Addressing/URL/uri-spec.html
Proxy transparente
Também conhecido como um proxy de interceptação, proxy inline ou proxy forçado, um proxy transparente intercepta uma comunicação normal na camada de rede sem necessitar de qualquer configuração do cliente específica. Os clientes não precisam estar cientes da existência do proxy. Um proxy transparente normalmente está localizado entre o cliente e a Internet, com o proxy realizando algumas das funções de um gateway ou roteador.
-
RFC 2616 (Protocolo de Transferência de Hipertexto - HTTP/1.1) oferece definições padrões:
"Proxy transparente é o que não modifica o pedido ou resposta para além do que é necessário para a autenticação e identificação do proxy".
"Proxy não transparente' é o que modifica a solicitação ou resposta, a fim de fornecer algum serviço adicional ao agente de usuário, como serviços de grupo de anotação, transformação de tipo de mídia, redução de protocolo ou filtragem de anonimato".
Propósito
Proxies de interceptação são normalmente usados em empresas para impor a política de uso aceitável e para aliviar as sobrecargas administrativas, uma vez que nenhuma configuração do navegador do cliente é necessária. Esta segunda razão entretanto é mitigada por recursos como política de grupo do Active Directory ou detecção de proxy automática ou via DHCP.
Proxies de interceptação também são normalmente usados por PSIs em alguns países para economizar largura de banda e melhorar os tempos de resposta ao cliente por meio do cache. Isto é mais comum em países onde a largura de banda é mais limitada (e.g. nações insulares) ou devem ser pagas.
Problemas
O desvio / intercepção de uma conexão TCP cria vários problemas. Em primeiro lugar o IP e a porta de destino original devem de alguma forma ser comunicados ao proxy. Isso nem sempre é possível (por exemplo, onde o gateway e o proxy residem em máquinas diferentes). Existe uma classe de ataques entre sites que dependem de certos comportamentos de interceptação de proxies que não verificam ou não têm acesso a informações sobre o destino original (interceptado).
Proxy aberto
Um proxy aberto é um servidor proxy acessível por um internauta. Geralmente, um servidor proxy permite aos usuários, dentro de um grupo na rede, o estoque e o repasse de serviços da Internet, igualmente ao DNS ou páginas web para reduzir e controlar a banda larga utilizada pelo grupo. Com um proxy aberto, entretanto, qualquer usuário da Internet é capaz de usar o serviço de repassagem (forwarding).
Vantagens
Um proxy aberto anônimo permite aos usuários conciliarem os seus endereços IP (e, consequentemente, ajudar a preservar o anonimato e manter a segurança) enquanto navega pela web ou usando outros serviços da Internet. Apesar de mal intencionados poderem fazer uso do anonimato para abusar de serviços, o cidadão de um país de regime repressivo, por exemplo, pode aproveitar-se da habilidade do proxy para acessar sites proibidos no seu país. Vários sites oferecem, com regularidade, listas atualizadas de proxies abertos.
Desvantagens
É possível para um computador rodar como um servidor proxy aberto, sem que o dono tenha conhecimento da invasão. Isto pode ser causado por mudanças na configuração do programa instalado do proxy, ou por infecção de um vírus ou cavalo de tróia. Nesse último caso, o computador infectado é chamado de "computador escravo". Usar um proxy aberto é um alto risco para o operador do servidor; oferecer um servidor proxy anônimo pode causar sérios problemas legais para o dono.
Tais serviços são frequentemente usados para invadir sistemas e acessar outros produtos ou serviços ilegais. Ademais, tal proxy pode causar alto uso de banda larga, resultando em maior latência na subrede e violação dos limites de banda. Um proxy aberto mal configurado pode, também, permitir acesso a subredes privadas, ou DMZ (Em segurança de computadores, uma DMZ ou zona desmilitarizada (do inglês demilitarized zone ou DMZ), também conhecida como rede de perímetro, é uma sub-rede física ou lógica que contém e expõe serviços de fronteira externa de uma organização a uma rede maior e não confiável, normalmente a Internet): este é um importante requisito de segurança a ser considerado por uma empresa, ou, até, redes domésticas, dado que computadores que, normalmente, estão fora de risco ou com firewall ativada também podem ser atacados.
Muitos proxies abertos são lentos, chegando a taxas mais baixas que 14,4kbit/s, ou ainda menos de 300bit/s, enquanto noutros casos a velocidade é variável. Alguns, como o 'PlanetLab', são mais velozes e foram intencionalmente direcionados ao uso público.
Sendo os proxies abertos considerados abusivos, inúmeros métodos foram desenvolvidos para detectá-los e recusar seus serviços. As redes IRC com políticas de uso estritas testam, automaticamente, sistemas de clientes para tipos conhecidos de proxies abertos. Assim sendo, um servidor de correio pode ser configurado para automaticamente testar envios para proxies abertos, fazendo uso de programas como o 'proxycheck'. Recentemente, mais e mais servidores de correio são configurados fora da caixa para consultar diversos servidores DNSBL (Domain Name System-based Blackhole List (DNSBL) or Real-time Blackhole List (RBL) is an effort to stop email spamming.), com o intuito de bloquear spam; alguns destes DNSBLs também listam proxies abertos.
Legalidade
Temendo pelo que seus cidadãos veem na Internet, muitos governos totalitários frequentemente empregam rastreadores de IP, atentando contra a privacidade do cidadão. Muitos são apanhados em flagrante e punidos perante a lei.
Proxy anônimo
Um proxy anônimo é uma ferramenta que se esforça para fazer atividades na Internet sem vestígios: acessa a Internet a favor do usuário, protegendo as informações pessoais ao ocultar a informação de identificação do computador de origem. O operador do proxy ainda pode relacionar as informações dos usuários com as páginas vistas e as informações enviadas ou recebidas. Quem não quer depender de um só operador proxy usa uma cadeia de diferentes proxies. Se um dos proxies da cadeia não colaborar com os outros e não guardar as informações dos usuários, torna-se impossível identificar os usuários através do número IP.
Também há redes de computadores que atuam cada um como um proxy, formando assim cadeias de proxies grátis que procuram as rotas do tráfego automaticamente. São redes como a I2P — A Rede Anónima[1]. Além disso, há medidas contra a análise de tráfego. Através dos proxies é possível enviar mensagens eletrônicas anônimas e visitar páginas na Internet de forma anônima. Também há mensageiros simples e anônimos, o IRC e o intercâmbio de arquivos.
Webproxy
Um webproxy é um tipo de proxy que funciona sem a necessidade de configuração do navegador. Funcionam com interface web. A maioria é desenvolvida em PHP, tendo projetos open-sources como PHPMyProxy e PHProxy já prontos para a hospedagem. Apresentam problemas com sites que fazem uso de sessões e, muitas vezes também, não lidam bem com cookies.
Anonimidade?
Alguns donos de proxies incluem o registro de logs (relatórios) em seus servidores, para diminuir problemas legais. Guardam as requisições e o endereço IP original do usuário. Além disso, alguns enviam cabeçalhos HTTP, como X-Powered-by, contendo o endereço IP original do usuário.
Uso
Proxys são mais utilizados em salas escolares de informática, empresas e outros locais onde se precisa dividir a Internet entre vários computadores. Além disso, proxies abertos e anônimos também são frequentemente utilizados em países onde a Internet é censurada ou onde ocorrem guerras, para denunciar constantemente os últimos acontecimentos.
Proxy Reverso
Um proxy reverso é um servidor de rede geralmente instalado para ficar na frente de um servidor Web. Todas as conexões originadas externamente são endereçadas para um dos servidores Web através de um roteamento feito pelo servidor proxy, que pode tratar ele mesmo a requisição ou encaminhar a requisição toda ou parcialmente a um servidor Web, que tratará dela.[1][2][3][4]
Um proxy reverso repassa o tráfego de rede recebido para um conjunto de servidores, tornando-o a única interface para as requisições externas. Por exemplo, um proxy reverso pode ser usado para balancear a carga de um cluster de servidores Web. O que é exatamente o oposto de um proxy convencional, que age como um despachante para o tráfego de saída de uma rede, representando as requisições dos clientes internos para os servidores externos à rede a qual o servidor proxy atende.
Principais características
Segurança
O servidor proxy pode oferecer uma camada adicional de defesa através da separação ou isolamento do servidor que está por trás de um proxy reverso. Essa configuração pode inclusive proteger os demais servidores da rede, principalmente pela obscuridade.
Criptografia
A criptografia SSL pode ser delegada ao próprio servidor proxy, em vez dos servidores Web. Nesse caso, o servidor proxy pode ser dotado de aceleradores criptográficos de alta performance.
Uma conexão utilizando SSL é sempre iniciada pelo cliente. Quando um usuário solicita a conexão comum site seguro, o navegador web (Firefox, Internet Explorer, Opera, Chrome, etc.)
solicita o envio do Certificado Digital e verifica se:
a) O certificado enviado é confiável.
b) O certificado é válido.
c) O certificado está relacionado com o site que o enviou.
Uma vez que as informações acima tenham sido confirmadas, a chave pública é enviada e as mensagens podem ser trocadas. Uma mensagem que tenha sido criptografada com uma chave pública somente poderá ser decifrada com a sua chave privada (simétrica) correspondente. Pense na mensagem como sendo uma fechadura e que ela possui duas chaves, umas para trancar (criptografar) e outra para destrancar (decifrar) a porta. Um servidor web protegido pelo protocolo SSL possui uma URL que começa em "https://",
onde o S significa “secured” (seguro, protegido).
Alguns algoritmos famosos de criptografia utilizam o protocolo SSL:
DES e DSA - algoritmo de criptografia usado pelo governo americano.
o KEA - usado para a troca de chaves pelo governo americano.
o MD5 – muito usado por desenvolvedores de software para que o usuário tenha certeza que o aplicativo não foi alterado.
o RSA - Algoritmo de chave pública para criptografia e autentificação.
o SHA-1 -também usado pelo governo americano.
-
A versão 3.0 do SSL exige a autenticação de ambas as partes envolvidas na troca de mensagens. Ou seja, tanto cliente quanto servidor deve fazer autenticação e afirmar que são que dizem ser.
Balanceamento de carga
O proxy reverso pode distribuir a carga para vários servidores, cada servidor responsável por sua própria aplicação. Dependendo da arquitetura da rede onde o servidor proxy reverso está instalado, o proxy reverso pode ter que modificar as URLs válidas externamente, para os endereços da rede interna.
Cache
Um proxy reverso pode aliviar a carga dos servidores Web através de um cache para o conteúdo estático, como, por exemplo, imagens, e também conteúdo dinâmico, como, por exemplo, uma pagina HTML gerada por um Sistema de Gerenciamento de Conteúdo. Um cache desse tipo pode satisfazer uma quantidade considerável de requisições, reduzindo de forma significativa o servidor Web. Outro termo utilizado é Acelerador Web. Essa técnica é utilizada nos servidores da Wikipédia.
Compressão
Um servidor proxy pode otimizar e comprimir o conteúdo, tornando o acesso mais rápido.
Colher de chá
Uma página dinamicamente gerada pode ser produzida e enviada instantaneamente para o servidor proxy, que pode enviá-la aos poucos para o cliente requisitante. A aplicação Web não precisa ficar esperando (e consumindo recursos do servidor) porque o cliente apresenta restrições de capacidade para receber conteúdo
solicitado.
Cache
Na área da computação, cache é um dispositivo de acesso rápido, interno a um sistema, que serve de intermediário entre um operador de um processo e o dispositivo de armazenamento ao qual esse operador acede. A principal vantagem na utilização de um cache consiste em evitar o acesso ao dispositivo de armazenamento - que pode ser demorado -, armazenando os dados em meios de acesso mais rápidos.
O uso de memórias cache visa obter uma velocidade de acesso a memória próxima da velocidade de memórias mais rápidas, e ao mesmo tempo disponibilizar no sistema uma memória de grande capacidade, a um custo similar de memórias de semicondutores mais baratas.
Nos dispositivos de armazenamento
Com os avanços tecnológicos, vários tipos de cache foram desenvolvidos. Atualmente há cache em processadores, discos rígidos, sistemas, servidores, nas placas-mãe, clusters de bancos de dados, entre outros. Qualquer dispositivo que requeira do usuário uma solicitação/requisição a algum outro recurso, seja de rede ou local, interno ou externo a essa rede, pode requerer ou possuir de fábrica o recurso de cache.
Por ser mais caro, não é financeiramente viável que o recurso mais rápido seja usado para armazenar todas as informações. Sendo assim, usa-se o cache para armazenar apenas as informações mais frequentemente usadas. Nas unidades de disco também conhecidas como discos rígidos (HD) também existem chips de cache nas placas eletrônicas que os acompanham. Como exemplo, a unidade Samsung de 160 GB possui 8 MB de cache. No caso da informática, o cache é útil em vários contextos:
-
nos casos dos processadores, em que cache disponibiliza alguns dados já requisitados e outros a processar;
-
no caso dos navegadores web, em que as páginas são guardadas localmente para evitar consultas constantes à rede (especialmente úteis quando se navega por páginas estáticas);
-
no caso das redes de computadores, o acesso externo, ou à Internet, se dá por meio de um software que compartilha a conexão ou link, software este também chamado de proxy, que tem por função rotear as requisições a IPs externos à rede que se encontra. Os proxys têm capacidade de caching: ao armazenar o conteúdo de páginas web já visitadas pelos usuários da rede na qual faz parte e fornecer esse conteúdo às novas requisições, minimizam o consumo do de largura de banda e agilizam a navegação;
-
os servidores web também podem dispor caches configurados pelo administrador, que variam de tamanho conforme o número de page views que o servidor tem.
Cache de disco
O cache de disco representa uma pequena quantidade de memória incluída na placa lógica do HD. Tem como principal função armazenar as últimas trilhas lidas pelo HD. Esse tipo de cache evita que a cabeça de leitura e gravação passe várias vezes pela mesma trilha, pois como os dados estão no cache, a placa lógica pode processar a verificação de integridade a partir dali, acelerando o desempenho do HD, já que o mesmo só requisita a leitura do próximo setor assim que o último setor lido seja verificado.
Operação
Um cache é um bloco de memória para o armazenamento temporário de dados que possuem uma grande probabilidade de serem utilizados novamente.
Uma definição mais simples de cache poderia ser: uma área de armazenamento temporária onde os dados frequentemente acedidos são armazenados para acesso rápido.
Um cache é feito de uma fila de elementos. Cada elemento tem um dado que é a cópia exata do dado presente em algum outro local (original). Cada elemento tem uma etiqueta que especifica a identidade do dado no local de armazenamento original, que foi copiado.
Quando o cliente do cache (CPU, navegador etc.) deseja aceder a um dado que acredita estar no local de armazenamento, primeiramente ele verifica o cache. Se uma entrada for encontrada com uma etiqueta correspondente ao dado desejado, o elemento do cache é então utilizado ao invés do dado original. Essa situação é conhecida como cache hit (acerto do cache). Como exemplo, um navegador poderia verificar o seu cache local no disco para ver se tem uma cópia local dos conteúdos de uma página Web numa URL particular. Nesse exemplo, a URL é a etiqueta e o conteúdo da página é o dado desejado. A percentagem de acessos que resultam em cache hits é conhecida como a taxa de acerto (hit rate ou hit ratio) do cache.
Uma situação alternativa, que ocorre quando o cache é consultado e não contém um dado com a etiqueta desejada, é conhecida como cache miss (erro do cache). O dado então é copiado do local original de armazenamento e inserido no cache, ficando pronto para o próximo acesso.
Se o cache possuir capacidade de armazenamento limitada (algo comum de acontecer devido ao seu custo), e não houver mais espaço para armazenar o novo dado, algum outro elemento deve ser retirado dela para que liberte espaço para o novo elemento. A forma (heurística) utilizada para selecionar o elemento a ser retirado é conhecida como política de troca (replacement policy). Uma política de troca muito popular é a LRU (least recently used), que significa algo como “elemento recentemente menos usado”.
Quando um dado é escrito no cache, ele deve ser gravado no local de armazenamento em algum momento. O momento da escrita é controlado pela política de escrita (write policy). Existem diferentes políticas.
A política de write-through (algo como “escrita através”) funciona da seguinte forma: a cada vez que um elemento é colocado no cache, ele também é gravado no local de armazenamento original. Alternativamente, pode ser utilizada a política de write-back (escrever de volta), onde as escritas não são diretamente espelhadas no armazenamento. Ao invés, o mecanismo de cache identifica quais de seus elementos foram sobrepostos (marcados como sujos) e somente essas posições são colocadas de volta nos locais de armazenamento quando o elemento for retirado do cache. Por essa razão, quando ocorre um cache miss (erro de acesso ao cache pelo fato de um elemento não existir nele) em um cache com a política write-back, são necessários dois acessos à memória: um para recuperar o dado necessário e outro para gravar o dado que foi modificado no cache.O mecanismo de write-back pode ser accionado por outras políticas também. O cliente pode primeiro realizar diversas mudanças nos dados do cache e depois solicitar ao cache para gravar os dados no dispositivo de uma única vez.
Os dados disponíveis nos locais de armazenamento original podem ser modificados por outras entidades diferentes, além do próprio cache. Nesse caso, a cópia existente no cache pode se tornar inválida. Da mesma forma, quando um cliente atualiza os dados no cache, as cópias do dado que estejam presentes em outros caches se tornarão inválidas. Protocolos de comunicação entre gerentes de cache são responsáveis por manter os dados consistentes e são conhecidos por protocolos de coerência.
Princípio da localidade de referência
É a tendência de o processador ao longo de uma execução referenciar instruções e dados da memória principal localizados em endereços próximos. Tal tendência é justificada devido as estruturas de repetição e as estruturas de dados, vetores e tabelas utilizarem a memória de forma subsequente (um dado após o outro). Assim a aplicabilidade do cache internamente ao processador fazendo o intermédio entre a memória principal e o processador de forma a adiantar as informações da memória principal para o processador.
Tipos de memória cache
Os tipos de memória cache mais conhecidos são:
-
Mapeamento direto: cada bloco da memória principal é mapeado para uma linha do cache;
-
Mapeamento associativo: um bloco da memória principal pode ser carregado para qualquer linha do cache;
-
Mapeamento associativo por conjunto (N-way): meio termo direto e o associativo.
Ausência de conteúdo no cache - CACHE MISS
Quando o processador necessita de um dado, e este não está presente no cache, ele terá de realizar a busca diretamente na memória RAM, utilizando wait states e reduzindo o desempenho do computador. Como provavelmente será requisitado novamente (localidade temporal) o dado que foi buscado na RAM é copiado no cache.
Cache em níveis
Com a evolução na velocidade dos dispositivos, em particular nos processadores, o cache foi dividido em níveis, já que a demanda de velocidade a memória é tão grande que são necessários caches grandes com velocidades altíssimas de transferência e baixas latências. Sendo muito difícil e caro construir memórias caches com essas características, elas são construídas em níveis que se diferem na relação tamanho X desempenho.
Cache L1
Uma pequena porção de memória estática presente dentro do processador. Em alguns tipos de processador, como o Pentium II, o L1 é dividido em dois níveis: dados e instruções (que "dizem" o que fazer com os dados). O primeiro processador da Intel a ter o cache L1 foi o i486 com 8KB. Geralmente tem entre 16KB e 128KB; hoje já encontramos processadores com até 16MB à 32MB de cache.
Cache L2
Em função da capacidade reduzida do cache L1, foi desenvolvido o cache L2, com mais memória que o cache L1. Ela é mais um caminho para que a informação requisitada não tenha que ser procurada na lenta memória principal. Alguns processadores colocam esse cache fora do processador, por questões econômicas, pois um cache grande implica num custo grande, mas há exceções, como no Pentium II, por exemplo, cujas caches L1 e L2 estão no mesmo cartucho, que está o processador. A memória cache L2 é, sobretudo, um dos elementos essenciais para um bom rendimento do processador mesmo que tenha um clock baixo. Um exemplo prático é o caso do Intel Itanium 9152M (para servidores) que tem apenas 1.6 GHz de clock interno e supera em desempenho o atual Intel Extreme, pelo fato de possuir uma memória cache de 24MB.
Quanto mais alto é o clock do processador, mais este aquece e mais instável se torna. Os processadores Intel Celeron têm um fraco desempenho por possuir menos memória cache L2. Um Pentium M 730 de 1.6 GHz de clock interno, 533 MHz FSB e 2 MB de cache L2, tem rendimento semelhante a um Intel Pentium 4 2.4 GHz, aquece muito menos e torna-se muito mais estável e bem mais rentável do que o Intel Celeron M 440 de 1.86 GHz de clock interno, 533 MHz FSB e 1 MB de cache L2.
Cache L3
Terceiro nível de cache de memória. Inicialmente utilizado pelo AMD K6-III (por apresentar o cache L2 integrado ao seu núcleo), utilizava o cache externo presente na placa-mãe como uma memória de cache adicional. Ainda é um tipo de cache raro devido a complexidade dos processadores atuais, com suas áreas chegando a milhões de transístores por micrômetros ou nanômetros de área.
É possível a necessidade futura de níveis ainda mais elevados de cache, como L4 e assim por diante.
Caches inclusivos e exclusivos
Caches Multi-level introduzem novos aspectos na sua implementação. Por exemplo, em alguns processadores, todos os dados no cache L1 devem também estar em algum lugar no cache L2. Estes caches são estritamente chamados de inclusivos. Outros processadores (como o AMD Athlon) têm caches exclusivos - os dados podem estar no cache L1 ou L2, nunca em ambos. Ainda outros processadores (como o Pentium II, III, e 4 de Intel), não requerem que os dados no cache L1 residam também no cache L2, embora possam frequentemente fazê-lo. Não há nenhum nome universal aceitado para esta política intermediária, embora o termo inclusivo seja usado.
A vantagem de caches exclusivos é que são capazes de armazenarem mais dados. Esta vantagem é maior quando o cache L1 exclusivo é de tamanho próximo ao cache L2, e diminui se o cache L2 for bastante acoplado ao núcleo, as vezes maior do que o cache L1. Quando o L1 falha e o L2 acerta acesso, a linha correta do cache L2 é trocada com uma linha no L1. Esta troca é um problema, uma vez que a quantidade de tempo para tal troca ser realizada é relativamente alta.
Uma das vantagens de caches estritamente inclusivos é que quando os dispositivos externos ou outros processadores em um sistema multiprocessado desejam remover uma linha do cache do processador, necessitam somente mandar o processador verificar o cache L2. Nas hierarquias de cache exclusiva, o cache L1 deve ser verificado também.
Uma outra vantagem de caches inclusivos é que um cache maior pode usar linhas maiores do cache, que reduz o tamanho das Tags do cache L2. (Os caches exclusivos requerem ambos os caches teres linhas do mesmo tamanho, de modo que as linhas do cache possam ser trocadas em uma falha no L1 e um acerto no L2).
Tamanho do cache
Quando é feita a implementação da memória cache, alguns aspectos são analisados em relação a seu tamanho:
-
a relação acerto/falha;
-
tempo de acesso a memória principal sera mais lenta;
-
o custo médio, por bit, da memória principal, do cache L1 e L2;
-
o tempo de acesso do cache L1 ou L2;
-
a natureza do programa a ser executado no momento é inferior.
Técnicas de escrita de dados do cache
Técnicas de "Write Hit"
Write-Back Cache
Usando esta técnica a CPU escreve dados diretamente no cache, cabendo ao sistema a escrita posterior da informação na memória principal. Como resultado, o CPU fica livre mais rapidamente para executar outras operações. Em contrapartida, a latência do controlador pode induzir problemas de consistência de dados na memória principal, em sistemas multiprocessados com memória compartilhada. Esses problemas são tratados por protocolos de consistência do cache.
Exemplo:
A escrita de um endereço é feita inicialmente numa linha do cache, e somente no cache. Quando mais tarde algum novo endereço precisar desta linha do cache, estando esta já ocupada, então o endereço inicial é guardado na memoria e o novo endereço ocupa-lhe o lugar na respectiva linha do cache.
Para reduzir a frequência de escrita de blocos de endereços na memória aquando da substituição é usado um "dirty bit", este é um bit de estado, ou seja, quando o endereço é instanciado inicialmente numa linha do cache, estando essa linha vazia, o valor inicial é implicitamente '0', quando o bloco do endereço é modificado(quando ocorre uma substituição) o valor inicial passa a '1' e diz-se que o bloco do endereço está "dirty".
Vantagens
-
a escrita ocorre à velocidade do cache;
-
escritas múltiplas de um endereço requerem apenas uma escrita na memória;
-
consome menos largura de banda.
Desvantagens
-
difícil de implementar;
-
nem sempre existe consistência entre os dados existentes no cache e na memória;
-
leituras de blocos de endereços no cache podem resultar em escritas de blocos de endereços "dirty" na memoria.
Write-Through Cache
Quando o sistema escreve para uma zona de memória, que está contida no cache, escreve a informação, tanto na linha específica do cache como na zona de memória ao mesmo tempo. Este tipo de caching providencia pior desempenho do que Write-Back Cache, mas é mais simples de implementar e tem a vantagem da consistência interna, porque o cache nunca está dessincronizada com a memória como acontece com a técnica Write-Back Cache.
Vantagens
-
fácil de implementar;
-
um "cache-miss" nunca resulta em escritas na memória;
-
a memória tem sempre a informação mais recente.
Desvantagens
-
a escrita é lenta;
-
cada escrita necessita de um acesso à memória;
-
consequentemente usa mais largura de banda da memória.
Técnicas de "Write Miss"
Write Allocate
O bloco de endereço é carregado na ocorrência seguindo-se uma ação de "write hit".
O "Write Allocate" é usado com frequência em caches de "Write Back".
No Write Allocate
O bloco de endereço é diretamente modificado na memória, não é carregado no cache.
O "No Write Allocate" é usado frequentemente em caches de "Write Through".