
ARQUITETURA DE
COMPUTADORES
A evolução da informática foi caracterizada pelo desenvolvimento de computadores com as mais diversas características, traduzidas pelos diferentes parâmetros, cada vez mais conhecidos da maioria de usuários de computador: a CPU adotada, a capacidade de memória, a capacidade do disco rígido, a existência de memória cache e outros menos conhecidos. A definição destes parâmetros e a forma como os diversos componentes de um computador são organizados, define aquilo que é conhecido por arquitetura de computador e vai determinar aspectos relacionados à qualidade, ao desempenho e à aplicação para a qual o computador vai ser orientado.[1][2]
Existem vários modos de uso do termo, que podem se referir a:
-
desenho da arquitetura da CPU do computador, o seu conjunto de instruções, "addressing modes" e técnicas, tais como paralelismo SIMD e MIMD.
-
termo também utilizado com significado análogo, ou semelhante, a Arquitetura de microprocessadores (RISC x CISC).
-
arquiteturas de hardware mais generalizadas, tais como computação em cluster e arquiteturas NUMA (acesso não-uniforme à memória).
-
utilização menos formal do termo, referindo-se a uma descrição dos requisitos (especialmente requisitos de velocidades e interligação) ou implementação do design para as várias partes de um computador, tais como memória, placa-mãe, periféricos eletrônicos ou, mais frequentemente, CPU.
A arquitetura é frequentemente definida como o conjunto de atributos da máquina que um programador deve compreender para que consiga programar o computador específico com sucesso, ou seja, para que consiga compreender o que o programa irá fazer quando da sua execução. Por exemplo, parte da arquitetura são as instruções e o raio de operadores manipulados por elas. De uma maneira semelhante, a frequência em que o sistema opera não é incluída na arquitetura. Esta definição revela as duas principais considerações dos arquitetos de computadores: desenhar hardware que se comporta como o programador pensa que se irá comportar e utilizar implementações existentes de tecnologias (por exemplo, semicondutores), para construir o melhor computador possível. A segunda consideração é frequentemente referida como a microarquitetura.[3]
História
A expressão "arquitetura de computadores", na literatura, pode ser atribuída a Lyle R. Johnson, Muhammad Usman Khan e Frederick P. Brooks, Jr. Em 1959, eram membros do departamento de Organização de Máquinas da IBM.
Johnson teve a oportunidade de escrever uma comunicação de pesquisa proprietária sobre Strech, um supercomputador desenvolvido pela IBM para o Laboratório Nacional de Los Alamos. Na tentativa de caracterizar o seu nível desejado de detalhe, ele observou que sua descrição de formatos, tipos de instruções, os parâmetros de hardware e melhorias de velocidade foi no nível de "arquitetura do sistema" - Um termo que parecia ser mais útil do que "organização de máquina".
Posteriormente, Brooks, um dos projetistas do Strech, começou o capítulo 2 de um livro (Planning a Computer System: Project Stretch, ed W. Buchholz, 1962), escrevendo: "Arquitetura de computadores, como outra arquitetura, é a arte de determinar as necessidades do usuário de uma estrutura e, possível dentro das limitações econômicas e tecnológicas."
Brooks passou a desempenhar um papel no desenvolvimento do IBM System/360
(agora chamado de IBM System z) linha de computadores,
onde a "arquitetura"ganhou moeda como um substantivo
com a definição como "o que o usuário precisa saber".
Mais tarde, o mundo da informática, empregaria o termo,
em formas muito menos explícitas.
Memória virtual
Outro problema recorrente envolve a memória virtual.
Historicamente, a memória de acesso aleatório (RAM) foi centenas de vezes mais cara que o armazenamento mecânico rotativo, isto é, discos rígidos, num computador moderno.
O processador só pode executar uma instrução que esteja na memória real. O mecanismo de Memória Virtual divide a memória real em frames e divide um arquivo no disco em páginas de mesmo tamanho dos frames. No disco existem muito mais páginas do que frames na memória. Sempre que for preciso uma página é copiada da memória virtual (arquivo em disco) para um frame da memória real. Surge a necessidade de saber quando é preciso copiar. Surge a necessidade de saber se um frame pode ser descartado ou se precisa ser recopiado para sua página correspondente no arquivo em disco. Sempre que uma instrução é executada a partir de um frame o hardware controlador de memória virtual testa se o dado a que ela se refere já se encontra em algum frame. Se for o caso, uma interrupção ocorre para que a rotina de tratamento cuide de copiar do disco para a memória real uma página completa contendo o dado necessário.
Segmentação das instruções (pipeline)
O conjunto e instruções orienta fortemente como funcionará a segmentação de instruções. A ideia é análoga a linha de produções em série, mas utilizada na execução das instruções. Primeiro divide-se as instruções em pedaços menores de forma que uma instrução em código de máquina demore muitos ciclos curtos para ser executada. Depois disso o controle do microprocessador encarrega-se de executar várias instruções ao mesmo tempo, cada uma utilizando um pedaço distinto do processador. Isto tem como objetivo que na média cada instrução demore um ciclo curto para ser executada. Existem diversas complicações em instruções de desvio (condicionais), que são tratadas por paralelismo de código conhecida como threading (nome comercial da Intel Hyperthreading).
Arquitetura etiquetada
a pesquisa
Uma arquitectura etiquetada é, em ciências da computação, um tipo específico de arquitectura de computadores em que toda a palavra de memória constitui uma união etiquetada, sendo dividida entre um número de bits de dados e uma secção-etiqueta, que desempenha a função de descrever o tipo de dados, em particular como deverá ser interpretada ou, caso seja uma referência, o tipo do objecto a que se refere.
Dois exemplos notáveis de arquitecturas etiquetadas são as máquinas Lisp, que possuiam suporte para ponteiros etiquetados ao nível do hardware e opcode, e o grande sistema Burroughs.

Introdução à Arquitetura de Computadores
Hoje em dia, computadores estão por toda a parte. Uma pessoa comum utiliza-se deles diversas vezes ao dia, muitas vezes sem mesmo se dar conta disso. Pegue, por exemplo, um aparelho celular. Ele é um computador apesar de normalmente não pensarmos nele como um. Os aparelhos celulares de hoje em dia possuem muito mais capacidade do que os primeiros computadores. Carros também costumam ser equipados com computadores que entre outras coisas, podem controlar a emissão de gases poluentes, controlar o consumo de combustível e aumentar a segurança de passageiros. Ao usar muitos eletrodomésticos, também estamos usando computadores que costumam vir embarcados em alguns deles. Para sacar dinheiro no banco, utilizamos caixas eletrônicos, ou seja: computadores. Video-games e calculadoras também são exemplos de computadores dedicados à realização de uma determinada tarefa.
Computadores facilitam muito a nossa vida e são responsáveis por muitos aspectos de nossa sociedade. Eles nos ajudam em praticamente qualquer tarefa. Do projeto de um prédio até avançadas pesquisas científicas.
Neste wiki curso, você irá aprender os mistérios por trás do funcionamento destas fantásticas máquinas mostrando todos os segredos que se escondem por trás do gabinete de seu computador (e celular, e videogame, e calculadora...) e do funcionamento de um processador.
Introdução aos Programas de Computador
Computadores funcionam através de impulsos elétricos. Uma corrente elétrica só pode possuir dois estados diferentes: ativada e desativada. Por causa disso, computadores só são capazes de entender os sinais "ativado" e "desativado" que daqui para a frente serão chamados respectivamente de "1" e "0".
Podemos considerar o "1" e o "0" como as duas únicas letras que um computador pode usar para se comunicar. Isso contrasta bastante com o alfabeto do português, onde contamos com 23 letras. Entretanto, da mesma forma que com 23 letras podemos escrever infinitas palavras, com apenas duas, também conseguimos. De agora em diante, passaremos a usar o termo "bit" ao invés de "letra" quando nos referirmos à "linguagem" falada por computadores.
Como computadores são máquinas, eles são incapazes de fazer qualquer coisa que não foram instruídos a fazer. Um programa de computador (também chamado de software ou logicial) nada mais é do que um texto que explica à um computador o que ele deve fazer. Por exemplo, os bits 10000110010100000 representam uma instrução para o computador. O que ele significa depende de cada modelo de computador, pois cada um fala a sua própria linguagem. Ele poderia significar, por exemplo, uma instrução que indica que dois números que estão na memória da máquina sejam somados.
Os primeiros programadores de computadores precisavam ficar se comunicando com computadores utilizando-se apenas esses sinais binários. Imagine o quão chato e trabalhoso era programar naquela época. Só para você ter uma idéia, abaixo mostraremos um trecho de programa que serve para trocar de lugar dois números de memória em um processador do tipo MIPS (ele está escrito em linguagem de máquina):

Precisamos de 235 caracteres para escrevermos uma instrução tão simples na linguagem nativa de um processador MIPS. Mas... será que escrevemos tudo certo? Será que não cometemos nenhum erro? Perceba que além de chata e cansativa, esta linguagem também é difícil de ser entendida. É muito fácil cometer erros escrevendo esse monte de "1" e "0", principalmente porque é difícil de entender o que estamos escrevendo.
Os primeiros programadores, bastante cansados por terem um emprego tão chato que era escrever "1" e "0" sem parar, começaram a ter ideias para facilitar o trabalho. Uma idéia muito boa que eles tiveram era substituir cada instrução por algo representado por letras e que fosse mais fácil de entender. Depois que eles tivessem escrito o programa com base em letras, existiria um programa chamado montador que seria responsável por traduzir as letras em sequências de 1s e 0s. O programa do exemplo anterior, escrito com letras, ficaria assim (ele está escrito em linguagem de montagem):

Apesar desta nova linguagem ainda parecer complicada, imediatamente é possível perceber que é mais fácil trabalhar com ela do que com linguagem de máquina. Nela, cada instrução ocupa apenas uma linha e o nome da instrução é sempre representado por um conjunto de letras. Dessa forma, é mais fácil de programar, pois caso cometamos algum erro, ele é muito mais fácil de detectar. Além disso, a instrução que em linguagem de máquina precisa de 235 caracteres para ser escrita, em linguagem de montagem pode ser escrita com pouco menos de 100 caracteres. É mais rápido programar assim!
A linguagem de montagem (ou assembly) passou por muitas melhorias com o tempo. Entretanto, ela ainda é demasiadamente complicada. Ainda dá trabalho para entender o que queremos dizer com aquelas 7 instruções ali em cima. Foi isso que levou os primeiros programadores a pensar: "Se nós conseguimos criar um programa que traduz instruções escritas em linguagem de montagem para linguagem de máquina, então é possível criar um programa que traduza algo escrito em uma linguagem mais próxima da linguagem humana para a linguagem de montagem...". E foi isso que eles fizeram.
Com o tempo, uma série de outras linguagens de alto nível foram criadas. O objetivo delas era fazer com que humanos pudessem escrever comandos para os computadores de uma forma mais confortável. Um programa chamado compilador firaria responsável por traduzir a linguagem de alto nível para a linguagem de montagem e um montador traduziria a linguagem de montagem para a linguagem de máquina. Abaixo você vê o mesmo trecho de programa mostrado acima escrito na linguagem C:

Dessa vez conseguimos nos expressar em apenas 65 caracteres. O programa escrito desta forma é ainda mais legível que o anterior.
Resumindo: computadores só são capazes de entender linguagem de máquina (1 e 0). Toda linguagem de máquina (cada modelo de máquina fala uma língua diferente) pode ser expressa em uma linguagem de montagem (assembly), que é mais fácil de ser entendida. Para que programas em assembly possam ser entendidos pelo computador, eles precisam ser traduzidos com a ajuda de programas chamados montadores. Normalmente, quando nós programamos, usamos uma linguagem menos rudimentar que o assembly. Usamos uma linguagem de alto nível (existem centenas delas). Tudo aquilo que é escrito em linguagens de alto nível precisa ser passado para um programa chamado compilador que traduz o que foi escrito para assembly (ou então traduz direto para linguagem de máquina).
As vantagens de alto nível são bastante usadas pelos seguintes motivos:
-
São mais fáceis de serem aprendidas e usadas que o assembly ou linguagem de máquina.
-
Criar programas em linguagens de alto nível é mais rápido, pois precisamos de menos caracteres e cometemos menos erros.
-
Programas escritos em linguagens de alto nível podem ser entendidos por qualquer máquina, desde que passem por um compilador e montador desenvolvido para aquela máquina. Já programas escritos em assembly ou linguagem de máquina só funcionarão nas máquinas para as quais foram projetados. Não podem ser passados para máquinas de modelos diferentes.
Além de instruções escritas em alguma linguagem, programadores frequentemente usam algo chamado bibliotecas. As bibliotecas nada mais são do que instruções para as máquinas que são muito comuns em muitos tipos de programas. Graças à elas, todos os programas que precisam fazer alguma tarefa (como imprimir texto em uma folha de papel) não precisam especificar o que o computador deve fazer para realizar a impressão com sucesso. Basta indicar que deseja-se usar um conjunto de instruções de uma biblioteca que indica como fazer isso. Dessa forma, quando estamos programando, não precisamos escrever tudo aquilo que o computador precisa fazer para realizar uma tarefa. Nós podemos simplismente reaproveitar instruções usadas por outros programas.
Para gerenciar as bibliotecas usadas pelo computador e também permitir que mais de um programa utilize a máquina ao mesmo tempo, também foram criados programas chamados Sistemas Operacionais. A tarefa destes programas é justamente gerenciar recursos da máquina. Alguns exemplos de Sistemas Operacionais são o MS-DOS, FreeDOS, Windows, ReactOS, Unix, GNU/Linux, BSD, MacOS X e Solaris.
Computação Paralela
Computação paralela é uma forma de computação em que vários cálculos são realizados ao mesmo tempo,[1] operando sob o princípio de que grandes problemas geralmente podem ser divididos em problemas menores, que então são resolvidos concorrentemente (em paralelo). Existem diferentes formas de computação paralela: em bit, instrução, de dado ou de tarefa. A técnica de paralelismo já é empregada por vários anos, principalmente na computação de alto desempenho, mas recentemente o interesse no tema cresceu devido às limitações físicas que previnem o aumento de frequência de processamento.[2]
Com o aumento da preocupação do consumo de energia dos computadores, a computação paralela se tornou o paradigma dominante nas arquiteturas de computadores sob forma de processadores multinúcleo.[3] Computadores paralelos podem ser classificados de acordo com o nível em que o hardware suporta paralelismo. Computadores com multinúcleos ou multiprocessadores possuem múltiplos elementos de processamento em somente uma máquina, enquanto clusters, MPP e grades usam múltiplos computadores para trabalhar em uma única tarefa. Arquiteturas paralelas especializadas às vezes são usadas junto com processadores tradicionais, para acelerar tarefas específicas.
Programas de computador paralelos são mais difíceis de programar que sequenciais,[4] pois a concorrência introduz diversas novas classes de defeitos potenciais, como a condição de corrida. A comunicação e a sincronização entre diferentes subtarefas é tipicamente uma das maiores barreiras para atingir grande desempenho em programas paralelos. O aumento da velocidade por resultado de paralelismo é dado pela lei de Amdahl.
Visão geral
Tradicionalmente, o software tem sido escrito para ser executado sequencialmente. Para resolver um problema, um algoritmo é construído e implementado como um fluxo serial de instruções. Tais instruções são então executadas por uma unidade central de processamento de um computador. Somente uma instrução pode ser executada por vez; após sua execução, a próxima então é executada.[5]
Por outro lado, a computação paralela faz uso de múltiplos elementos de processamento simultaneamente para resolver um problema. Isso é possível ao quebrar um problema em partes independentes de forma que cada elemento de processamento pode executar sua parte do algoritmo simultaneamente com outros. Os elementos de processamento podem ser diversos e incluir recursos como um único computador com múltiplos processadores, diversos computadores em rede, hardware especializado ou qualquer combinação dos anteriores.[5]
O aumento da frequência de processamento foi o principal motivo para melhorar o desempenho dos computadores de meados da década de 1980 a 2004. Em termos gerais, o tempo de execução de um programa corresponde ao número de instruções multiplicado pelo tempo médio de execução por instrução. Mantendo todo o resto constante, aumentar a frequência de processamento de um computador reduz o tempo médio para executar uma instrução, reduzindo então o tempo de execução para todos os programas que exigem alta taxa de processamento (em oposição à operações em memória.)[6]
Leis de Amdahl e Gustafson
O tempo de execução e o aumento de velocidade de um programa com paralelismo. A curva azul ilustra o aumento linear que um programa teria no caso ideal, enquanto a curva roxa indica o aumento real. Da mesma forma, a curva amarela indica o tempo de execução no caso ideal (uma assímptota tendendo a zero), enquanto a curva vermelha indica o tempo de execução real (uma assímptota tendendo a um valor acima de zero)[10]
Teoricamente, o aumento de velocidade com o paralelismo deveria ser linear, de forma que dobrando a quantidade de elementos de processamento, reduz-se pela metade o tempo de execução. Entretanto, muitos poucos algoritmos paralelos atingem essa situação ideal. A maioria deles possui aumento de velocidade quase linear para poucos elementos de processamento, tendendo a um valor constante para uma grande quantidade de elementos.
O aumento de velocidade potencial de um algoritmo em uma plataforma de computação paralela é dado pela lei de Amdahl, formulada por Gene Amdahl na década de 1960.[11] Ela afirma que uma pequena porção do programa que não pode ser paralelizada limitará o aumento de velocidade geral disponível com o paralelismo. Qualquer problema matemática ou de engenharia grande tipicamente consistirá de diversas partes paralelizáveis e diversas partes sequenciais. A relação entre os dois é dada pela equação:
em que S é o aumento de velocidade do programa e P é a fração paralelizável. Se a porção sequencial de um programa representa 10% do tempo de execução, não se pode obter mais que dez vezes de aumento de velocidade, independente de quantos processadores são adicionados. Isso limita a utilidade da adição de mais unidades paralelas de execução.
A lei de Gustafson está realacionada com a de Amdahl. Ela pode ser formulada como:
em que P é o número de processadores, S é o aumento de velocidade e α é a parte não paralelizável do processo.[13] A lei de Amdahl assume um tamanho de problema fixo e que o tamanho da seção sequencial é independente do número de processadores, enquanto a lei de Gustafson não parte dessas premissas.


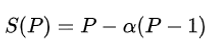


Uma das duas threads conseguirá bloquear a variável, enquanto a outra ficará esperando impossibilitada de continuar sua execução até que o desbloqueio seja feito. Ainda que tal bloqueio garante a execução correta do programa, ele pode tornar o programa consideravelmente mais lento.
Bloquear múltiplas variáveis usando bloqueios não atômicos introduz a possibilidade de deadlock. Um bloqueio atômico bloqueia diversas variáveis simultaneamente. Não podendo bloquear qualquer uma delas, todo o bloqueio falha. Se duas threads precisam bloquear as mesmas duas variáveis usando bloqueios não atômicos, é possível que cada uma das threads bloqueie uma variável distinta. Nesse caso, nenhuma thread pode continuar e o deadlock ocorre.
Nem todo paralelismo resulta em aumento de velocidade. Geralmente, como uma tarefa é dividida em diversas threads, tais threads gastam determinado tempo comunicando-se com outras. Eventualmente, o overhead da comunicação domina o tempo gasto para resolver o problema. Nesse caso, quanto mais paralelismo é feito, mais lento é o tempo total de execução, um efeito conhecido como lentidão paralela.
Modelos de consistência
Leslie Lamport definiu o conceito de consistência sequencial. Ele também é conhecido por ter criado o LaTeX
Linguagens de programação e computadores paralelos devem ter um modelo de consistência, também conhecido como modelo de memória, que define as regras de execução das operações em memória e como os resultados são produzidos.
Um dos primeiros modelos de consistência foi a consistência sequencial de Leslie Lamport. Tal modelo é a propriedade de que a execução de um programa paralelo produz o mesmo resultado que um programa sequencial. Especificamente, um programa é sequencialmente consistente se "… os resultados de qualquer de suas execuções é o mesmo se as operações de todos os processadores forem executadas em alguma ordem sequencial, e as operações de cada processador aparecem nessa sequência na ordem especificada pelo programa".[16]
Matematicamente, tais modelos podem ser representados de diversas formas. Introduzidas por Carl Adam Petri em sua tese de doutorado em 1962, as redes de Petri foram uma primeira abordagem para codificar as regras de modelos de consistência. Posteriormente a teoria de fluxos de dados foi construída, e arquiteturas de fluxo de dadoforam criadas para implementar fisicamente as ideias da teoria de fluxo de dado. A partir do final da década de 1970, álgebras de processo como cálculo de sistemas de comunicação e processos de comunicação serial foram desenvolvidos para permitir a modelagem algébrica de sistemas compostos por componentes que interagem. Adições mais recentes à família, como o cálculo pi, adicionaram a capacidade de modelar topologias dinâmicas. Lógicas como o TLA+ e modelos matemáticos como tracestambém foram desenvolvidos par descrever o comportamento de sistemas concorrentes.
Taxonomia de Flynn
Michael J. Flynn criou um dos primeiros sistemas de classificação para computadores e programas paralelos e sequenciais, atualmente conhecida como taxonomia de Flynn. O cientista classificou os programas e computadores por quantidade de fluxos de instruções, e por quantidade de dados usadas por tais instruções.
A classificação SISD equivale a um programa inteiramente sequencial, e a classificação SIMD é análoga a fazer a mesma operação repetidamente por um grande conjunto de dados. A classificação MISD raramente é usada, já os programas MIMD são os programas paralelos mais comuns.
Tipos de paralelismo
No bit
A partir do advento da tecnologia de fabricação de chip VLSI na década de 1970 até cerca de 1986, o aumento da velocidade na arquitetura de computador era obtido dobrando-se o tamanho da palavra, a quantidade de informação que o processador pode executar por ciclo.[17] Aumentar o tamanho da palavra reduz a quantidade de instruções que um processador deve executar para realizar uma operação em variáveis cujo tamanho é maior do que o da palavra.
Historicamente, microprocessadores de quatro bits foram substituídos por oito, então para dezesseis e então para trinta e dois. A partir de então, o padrão 32-bit se manteve na computação de uso geral por duas décadas. Cerca de 2003, a arquitetura 64-bit começou a ganhar mais espaço.
Na instrução
Em sua essência, um programa de computador é um fluxo de instruções executadas por um processador. Tais instruções podem ser reordenadas e combinadas em grupos que então são executados em paralelo sem mudar o resultado do programa. Isso é conhecido por paralelismo em instrução. Avanços nessa técnica dominaram a arquitetura de computador de meados da década de 1980 até meados da década de 1990.[18]
Processadores modernos possuem pipeline com múltiplos estágios. Cada estágio corresponde a uma ação diferente que o processador executa em determinada instrução; um processador com um pipeline de N estágios pode ter até N diferentes instruções em diferentes estágios de execução. O exemplo canônico é o processador RISC, com cinco estágios: instruction fetch, decode, execute, memory access e write back. O processador Pentium 4 possui um pipeline de 35 estágios.[19]
Além do paralelismo em instrução obtido com o pipeline, alguns processadores podem lidar com mais de uma instrução por vez. São conhecidos como processadores superescalares. As instruções podem ser agrupadas somente se não há dependência de dados entre elas. O algoritmo de marcador e o algoritmo de Tomasulo são duas das técnicas mais usadas para implementar reordenação de execução e paralelismo em instrução.
No dado
O paralelismo em dado está inerente a laços de repetição, focando em distribuir o dado por diferentes nós computacionais para serem processados em paralelo. Diversas aplicações científicas e de engenharia apresentam esse tipo de paralelismo.
Uma dependência por laço é a dependência de uma iteração do laço com a saída de uma ou mais iterações anteriores, uma situação que impossibilita a paralelização de laços. Por exemplo, considerando o seguinte pseudocódigo que calcula os primeiros números de Fibonacci.
Esse laço não pode ser paralelizado porque atual depende de si (anterior1) e anterior2, que são calculados em cada iteração. Como cada iteração depende do resultado da anterior, elas não podem ser realizadas em paralelo. Com o aumento do tamanho de um problema, geralmente aumenta-se a quantidade de paralelismo em dado disponível.[20]
Na tarefa
Paralelismo em tarefa é a característica de um programa paralelo em que diferentes cálculos são realizados no mesmo ou em diferentes conjuntos de dados.[21] Isso contrasta com o paralelismo em dado, em que o mesmo cálculo é feito em diferentes conjuntos de dados. Paralelismo em tarefa geralmente não é escalável com o tamanho do problema.[20]
Hardware
Memória e comunicação
A memória principal de um computador paralelo é compartilhada (compartilhada entre os elementos de processamento num único espaço de endereçamento) ou distribuída (cada elemento de processamento possui seu próprio espaço de endereçamento).[22] Memória distribuída se refere ao fato da memória ser logicamente distribuído, mas frequentemente isso também implica na distribuíção física. A memória distribuída e compartilhada é uma combinação das duas abordagens, em que cada elemento de processamento possui sua memória local e acessa a memória de outros processadores remotos. Acesso à memória local é geralmente mais rápido que acesso à memória remota.
Arquiteturas de computador em que cada elemento da memória principal pode ser acessado com a mesma latência e banda são conhecidas como sistemas de Acesso à Memória Unificado. Isso geralmente é feito por um sistema com somente memória compartilhada. Um sistema que não possui tal propriedade é conhecido como sistema de Acesso à Memória Não-Unificado, o que inclui sistemas que utilizam memória distribuída.
Computadores fazem uso de cache, memórias pequenas e rápidas localizadas próximo ao processador, e que armazenam cópias temporárias de valores e memória.
Computadores paralelos possuem dificuldades com caches que podem armazenar o mesmo valor em mais de um local, com a possibilidade de execução incorreta do programa. Tais sistemas existem um mecanismo de coerência de cache, que asseguram a execução correta. Desenvolver mecanismos de coerência de cache de alto desempenho é um problema muito difícil na arquitetura de computador. Como resultado, arquiteturas de memória compartilhada não escalonam tão bem quanto sistemas distribuídos.[22]
A comunicação dos processadores entre si e com as memórias pode ser implementada em hardware de várias formas, incluindo por memória compartilhada, barramento compartilhado ou uma rede interconectada. Para o último caso, deve haver uma forma de roteamento para permitir a troca de mensagens entre nós que não estão diretamente conectados.
Software
Linguagens de programação paralelas
Linguagens de programação, bibliotecas, API e modelos foram criados para programar computadores paralelos. Geralmente divide-se em classes de plataformas, baseadas nas premissas sobre a arquitetura de memória usada, incluindo memória compartilhada, memória distribuída ou memória compartilhada e distribuída. Linguagens de programação de memória compartilhada se comunicam ao manipularem variáveis de memória compartilhada. Exemplos de uso do modelo incluem POSIX Threads e OpenMP. Já a memória distribuída faz uso de troca de mensagens. Exemplos de uso do modelo incluem Message Passing Interface. Um conceito usado em na programação paralela é o valor futuro, quando uma parte do programa promete processar dados para outra parte de um programa em um momento futuro.
Paralelismo automático
A habilidade de um compilador realizar paralelismo automático de um programa sequencial é um dos assuntos mais estudados no campo de computação paralela. Entretanto, apesar de décadas de trabalho por pesquisadores de compiladores, pouco sucesso se teve na área.[23] Linguagens de programação paralelas de amplo uso continuam explícitas, isto é, requerendo a programação paralela propriamente dita; ou no máximo parcialmente implícitas, em que o programador fornece ao compilador diretivas para o paralelismo.
Aplicações
Com o desenvolvimento de computadores paralelos, torna-se mais viável resolver problemas anteriormente muito demorados para se executar. A computação paralela é usada em diversos campos, da bioinformática (para o enovelamento de proteínas) a economia (para simulações de matemática financeira). Tipos comuns de problemas encontrados em aplicações de computação paralela são:[24]
-
Álgebra linear densa
-
Álgebra linear esparsa
-
Métodos espectrais
-
Problemas N-body
-
Problemas de grades estruturadas
-
Problemas de grades não estruturadas
-
Visita de grafo
-
Métodos de ramificação e poda
-
Simulação de máquina de estado finito

H P C - Computação de alto desempenho
Computação de alto desempenho ou HPC (do inglês High-performance computing) se refere ao uso de supercomputadores ou clusters de vários computadores em tarefas que requerem grandes recursos de computação, nomeadamente simulações numéricas muito complicadas. Geralmente classificam-se como sistemas HPC aqueles cuja performance é de pelo menos alguns teraflops.
Um termo relacionado, computação de alto desempenho técnico (HPTC), geralmente se refere às aplicações de engenharia de computação baseada em cluster (como dinâmica de fluidos computacional e na construção e teste virtual de protótipos ). Recentemente, a HPC tem vindo a ser aplicada a negócios usos de supercomputadores baseados em cluster, tais como data warehouses, linha de negócios (LOB) e processamento de transações .
Computação de alto desempenho (HPC) é um termo que surgiu após o termo " supercomputadores ". HPC é por vezes utilizado como sinônimo de supercomputação, mas, em outros contextos, " supercomputador "é usado para se referir a um subconjunto mais poderoso de" computadores de alto desempenho ", e o termo" supercomputadores "torna-se um subconjunto de" alta performance computação. O potencial de confusão sobre o uso destes termos é aparente.
TOP 500
A lista dos poderosos computadores de alto desempenho, a maioria pode ser encontrada no TOP500.
A lista TOP500 o ranking mundial de 500 computadores mais rápidos de alta performance, medida pelo Alto Desempenho Linpack HPL) referência.
Nem todos os computadores listados, quer porque não são elegíveis (por exemplo, eles não podem correr o benchmark HPL) ou porque seus proprietários não tenham apresentado uma pontuação HPL (por exemplo, porque eles não desejam o tamanho do seu sistema para tornar a informação pública para a defesa razões).
Além disso, a utilização do benchmark Linpack único é controverso, em que nenhuma medida pode testar todos os aspectos de um computador de alto desempenho.Para ajudar a superar as limitações do teste Linpack, o governo dos EUA encomendou um dos seus criadores, o Dr. Jack Dongarra da Universidade do Tennessee, para criar um conjunto de testes de benchmark que inclui Linpack e outros, o chamado HPC Benchmark Challenge.
Aqueles suite evolução tem sido utilizado em alguns contratos HPC, mas, porque não é redutível a um único número, tem sido incapaz de superar a vantagem de publicidade do teste menos útil TOP500 Linpack. A lista TOP500 é atualizada duas vezes por ano, uma vez que em Junho no Conselho Europeu de ISC Supercomputing Conference e, novamente, em um EUA Supercomputing Conference, em novembro.
Muitas ideias para a nova onda da computação em grade foram originalmente emprestado de HPC.
No Brasil
Pode-se ter acesso a recursos computacionais de alto desempenho através do Sistema Nacional de Processamento de alto Desempenho (SINAPAD), rede de centros de computação de alto desempenho instituída pelo Ministério da Ciência, Tecnologia e Inovação (MCTI) e coordenada pelo Laboratório Nacional de Computação Científica. [1]

Sistema de Processamento Distribuído
Um sistema de processamento distribuído ou paralelo é um sistema que interliga vários nós de processamento (computadores individuais, não necessariamente homogéneos) de maneira que um processo de grande consumo seja executado no nó "mais disponível", ou mesmo subdividido por vários nós. Conseguindo-se, portanto, ganhos óbvios nestas soluções: uma tarefa qualquer, se divisível em várias subtarefas pode ser realizada em paralelo.
A nomenclatura geralmente utilizada neste contexto é HPC (High Performance Computing)
e/ou DPC (Distributed/Parallel Computing).
Desenvolvimento
Este é um assunto muito vasto e, embora com alguma idade, só em 2001 se começou a falar em padrões para estas soluções, que são utilizadas (em larga escala) geralmente nos meios científicos e outros de cálculo intensivo pela sua extensibilidade. São bastante flexíveis, já que permitem a coexistência de sistemas desenhados especificamente para isso (por exemplo, a arquitectura NUMA), de sistemas desktop, e mesmo de sistemas considerados obsoletos, mas não o suficiente para permitir a coexistência de soluções semelhantes.
Antes de avançar, será necessário distinguir um sistema de multiprocessamento paralelo (SMP) de um sistema distribuído. Para um sistema ser de processamento distribuído, uma ou várias unidades de processamento (CPU) estará separada fisicamente da(s) outra(s), enquanto que num sistema SMP todas as unidades de processamento se encontram na mesma máquina. Ambos sistemas são capazes de processamento paralelo, e qualquer um deles pode ser visto como elemento de um sistema distribuído!
Com os desenvolvimentos nesta área, surgiram soluções por software que fazem, geralmente (mas não necessariamente), alterações no núcleo do sistema operativo e que, na maioria dos casos, não são compatíveis entre elas, e dificilmente entre versões diferentes da mesma solução. Assentam, no entanto, em arquitecturas de comunicação padrão, como é o caso da Parallel Virtual Machine e Message Passing Interface. Resumidamente, estas arquitecturas conseguem transportar um processo (tarefa) e o seu contexto (ficheiros abertos, etc.) pela rede até outro nó. O nó que originou o processo passa, assim, a ser apenas um receptor dos resultados desse processo.
Actualmente, a principal barreira destes sistemas é implementar mecanismos de Inter-Process Communication (IPC), os Distributed IPC, dada a sua extrema complexidade.
Arquitetura
A Figura 1 ilustra as várias camadas de interoperabilidade de um sistema distribuído. Através do gateway a rede pública tem acesso a um supercomputador, sem ter conhecimento disso, dado que só conhece o gateway. Qualquer aplicação executada no gateway (preparada para ser paralelizada) pode ser distribuída por vários nós, entregando os resultados mais rápido do que se fosse processada por apenas um nó.
Definição
Um sistema distribuído segundo a definição de Andrew Tanenbaum é uma "coleção de computadores independentes entre si que se apresenta ao usuário como um sistema único e coerente";[1] outra definição, de George Coulouris, diz: "coleção de computadores autônomos interligados através de uma rede de computadores e equipados com software que permita o compartilhamento dos recursos do sistema: hardware, software e dados".
Assim, a computação distribuída consiste em adicionar o poder computacional de diversos computadores interligados por uma rede de computadores. A união desses diversos computadores com o objetivo de compartilhar a execução de tarefas, é conhecida como sistema distribuído.
Organização
Organizar a interação entre cada computador é primordial. Visando poder usar o maior número possível de máquinas e tipos de computadores, o protocolo ou canal de comunicação não pode conter ou usar nenhuma informação que possa não ser entendida por certas máquinas. Cuidados especiais também devem ser tomados para que as mensagens sejam entregues corretamente e que as mensagens inválidas sejam rejeitadas, caso contrário, levaria o sistema a cair ou até o resto da rede.
Outro fator de importância, é a habilidade de mandar softwares para outros computadores de uma maneira portável de tal forma que ele possa executar e interagir com a rede existente. Isso pode não ser possível ou prático quando usando hardware e recursos diferentes, onde cada caso deve ser tratado separadamente com cross-compiling ou reescrevendo software.
Modelos de computação distribuída
Peer-to-peer (P2P)
Ver artigo principal: Peer-to-peer Ponto-a-Ponto
É uma arquitetura de sistemas distribuídos caracterizada pela descentralização das funções na rede, onde cada nó realiza tanto funções de servidor quanto de cliente.
Objetos distribuídos
Semelhante ao peer-to-peer (do inglês peer-to-peer, que significa ponto-a-ponto) é um formato de rede de computadores em que a principal característica é descentralização das funções convencionais de rede, onde o computador de cada usuário conectado acaba por realizar funções de servidor e de cliente ao mesmo tempo. Seu principal objetivo é a transmissão de arquivos e seu surgimento possibilitou o compartilhamento em massa de músicas e filmes. Com a crescente utilização da rede P2P para este fim, cada vez mais surgem programas para este fim, porém nem sempre eles atendem às expectativas do usuário.
Diversas redes operam hoje em dia nestes moldes de compartilhamento, entre elas Kademlia, Gnutela, Kad Network e SoulSeek. Alguns programas valem a pena ser citados quando o assunto é compartilhamento P2P: μTorrent, BitTorrent, SoulSeek, Ares Galaxy, Shareaza, DreaMule, iMesh e Morpheus. Caso prefira, acesse a categoria de Compartilhadores P2P do Baixaki e conheça mais programas que operam deste modo.
Mas com um Middleware intermediando o processo de comunicação.
Hardware
A organização do hardware em sistemas com várias UCPs se dá por:
Sistemas paralelos
Ver artigo principal: Sistema de processamento paralelo
-
É constituído de vários processadores tipicamente homogêneos e localizados em um mesmo computador.
-
Multicomputadores - Cada processador possui sua própria memória local.
-
Multiprocessadores - Os processadores compartilham memória.
Arquiteturas
-
Multiprocessadores em barramento.
-
Multiprocessador.
-
Multiprocessador homogêneo.
-
Multiprocessador heterogêneo.
Software
-
Fracamente acoplados - um software que serve de interface entre o computador (hardware) e os humanos (peopleware) , que permite a execução de diversos outros softwares (aplicativos)....
-
Fortemente acoplados - permitem que máquinas e usuários de um sistema distribuído sejam fundamentalmente independentes e ainda interagir de forma limitada quando isto for necessário, compartilhando discos, impressoras e outros recursos.
Sistemas operacionais
-
Sistema operacional (SO) é um software que serve de interface entre o computador (hardware) e os humanos (peopleware) , que permite a execução de diversos outros softwares (aplicativos).
-
SO de máquinas monoprocessadas.
-
SO Multiprocessadores é uma extensão de SOs de máquinas monoprocessadas, a principal diferença sendo que os dados da memória são acessados por vários processadores e, portanto, necessitam de proteção com relação aos acessos concorrentes.
-
SOs Multicomputadores são uma alternativas para o buffering de mensagens e pontos de bloqueio, alguns SOs disponibilizam uma abstração de memória compartilhada.
-
SOs de rede: existe uma independência entre os computadores.
Sistemas fortemente acoplados Neste sistema existe vários processadores compartilhando uma memória, e gerenciado por apenas um S.O.
Múltiplos processadores permitem que vários programas sejam executados ao mesmo tempo e em tempo real.Com isso será possível aumentar a capacidade de computação adicionando apenas processadores.
Exemplos
-
os sistemas operacionais mais conhecidos hoje são: Windows, GNU/Linux, MacOS(Apple).
-
Um exemplo clássico de computação distribuída é o projeto Seti at home que visa procurar em sinais de rádio interplanetários algum vestígio de vida extraterrestre.
-
O exemplo mais moderno desse paradigma é o BOINC, que é um framework de grade computacional no qual diversos projetos podem rodar suas aplicações, como fazem os projetos World Community Grid, SETI@Home, ClimatePrediction.net, Einstein@Home, PrimeGrid e OurGrid.
Soluções
Software
Cluster
Um cluster (do inglês TESTE: 'grupo, aglomerado') consiste em computadores fracamente ou fortemente ligados que trabalham em conjunto, de modo que, em muitos aspectos, podem ser considerados como um único sistema. Diferentemente dos computadores em grade, computadores em cluster têm cada conjunto de nós, para executar a mesma tarefa, controlado e programado por software.[1]
História
A ideia inicial que conduz ao cluster foi desenvolvida na década de 1960 pela IBM como uma forma de interligar grandes mainframes, visando obter uma solução comercialmente viável de paralelismo. Nessa época, o sistema HASP (Houston Automated Spooling Program) da IBM e seu sucessor o JES (Job Entry System) proviam uma maneira de distribuir tarefas nos mainframes interligados. Pelo menos até 2001, a IBM suportava o cluster de mainframes através do Parallel Sysplex System, que permitia que hardware, sistema operacional, middleware e software de gerenciamento do sistema provessem uma notável melhora na performance e custo, permitindo que usuários de grandes mainframes continuassem utilizando as aplicações existentes.
O cluster ganhou força até que três tendências convergiram, nos anos 1980: microprocessadores de alta performance, redes de alta velocidade e ferramentas padronizadas para computação distribuída de alto desempenho. Uma quarta tendência possível é a crescente necessidade de poder de processamento para aplicações científicas e comerciais unida ao alto custo e a baixa acessibilidade dos tradicionais supercomputadores.
No final de 1993, Donald Becker e Thomas Sterling iniciaram um esboço de um sistema de processamento distribuído construído a partir de hardware convencional como uma medida de combate aos custos dos supercomputadores. No início de 1994, trabalhando no CESDIS, com o patrocínio do projecto HTPCC/ESS, criaram o primeiro cluster desse tipo, o projecto Beowulf.
O protótipo inicial era um cluster de 16 processadores DX4 ligados por dois canais Ethernet acoplados (Ethernet bonding). A máquina foi um sucesso instantâneo e esta ideia rapidamente se espalhou pelos meios académicos, pela NASA e por outras comunidades de pesquisa.
Tipos de cluster
Existem vários tipos de cluster. Os mais conhecidos são:
-
cluster de alto desempenho: também conhecido como cluster de alta performance, ele funciona permitindo que ocorra uma grande carga de processamento com um volume baixo de gigaflops em computadores comuns e utilizando sistema operacional gratuito, o que diminui seu custo;
-
cluster de alta disponibilidade: são clusters cujos sistemas conseguem permanecer ativos por um longo período de tempo e em plena condição de uso; sendo assim, podemos dizer que eles nunca param seu funcionamento; além disso, conseguem detectar erros se protegendo de possíveis falhas;
-
cluster para balanceamento de carga: esse tipo de cluster tem como função controlar a distribuição equilibrada do processamento. Requer um monitoramento constante na sua comunicação e em seus mecanismos de redundância, pois, se ocorrer alguma falha, haverá uma interrupção no seu funcionamento.
GRID COMPUTING
Computação em GRID (português europeu), computação em grade/grid (português brasileiro), ou ainda, grelha de cálculo (em inglês, grid computing), é um modelo computacional capaz de alcançar uma alta taxa de processamento dividindo as tarefas entre diversas máquinas, podendo ser em rede local ou rede de longa distância, que formam uma máquina virtual. Esses processos podem ser executados no momento em que as máquinas não estão sendo utilizadas pelo usuário, assim evitando o desperdício de processamento da máquina utilizada.
Na base da atual computação em grelha estão os aglomerado de computadores ou computadores localizados em diferentes centros de cálculo, ligados entre si por uma rede de alto débito (Largura de Banda), em Rede Privada Virtual - (VPN) por questões de segurança.
Razão da grade
Milhares de físicos em todo o mundo quereram aceder aos dados do grande colisor de hádrons (LHC) para os analisar, e o CERN decidiu construir uma infraestrutura distribuída para armazenar e tratar o astronómico fluxo de dados (25 petabytes = 25 milhões de gigabytes) gerados anualmente pelas experiências do LHC. Assim nasceu a WLCG sigla inglesa de Worldwide LHC Computing Grid.[1][2]
Antecedentes
Nos anos 90 uma nova infraestrutura de computação distribuída foi proposta visando auxiliar atividades de pesquisa e desenvolvimento científico. Vários modelos desta infra-estrutura foram especificados, dentre elas, a tecnologia em grade, em analogia às Redes Elétricas (power grids), se propõe em apresentar ao usuário como um computador virtual, a VPN, mascarando toda a infra-estrutura distribuída, assim como a rede elétrica para uma pessoa que utiliza uma tomada sem saber como a energia chega a ela.
Seu objetivo era casar tecnologias heterogêneas (e muitas vezes geograficamente dispersas) formando um sistema robusto, dinâmico e escalável onde se pudesse compartilhar processamento, espaço de armazenamento, dados, aplicações, dispositivos, entre outros. Foi o caso do SETI@home ou a dos cálculos para a fesabilidade do LHC do Cern com o LHC@home plataforma que com ajuda dos computadores pessoais ligados fora das horas de trabalho permitem ter muito poder de cálculo com pouca transferência de dados, e isso desde 2009.[3]
Uma outra tecnologia de grelha é a P2P (peer-to-peer) que permite a interconexão de computadores pessoais para se trocar dados, ficheiros, etc.
Visionários
Em si mesmo a computação em grade nasceu em setembro de 1997 aquando de uma reunião no Laboratório Nacional de Argonne sobre o tema "Construir uma grelha de cálculo". Em 1998, Ian Foster, desse mesmo laboratório, e Carl Kesselman, da Universidade de Califórnia em Los Angeles (UCLA), publicaram um trabalho chamado A grelha: plano para nova estrutura de cálculo - o que hoje é conhecido como a bíblia da grade[4]. Por seu lado Ian Foster já havia participado no projeto I-WAY e o duo Foster-Kesselman tinham publicado em 1997 um artigo intitulado Globus: uma caixa de ferramenta para infraestrutura meta-informática fazendo assim referência direta a Globus e ao seu predecessor, a meta-informatica.[5]
Histórico
Os antecedentes das atuais grelhas de cálculo foram utilizados há muito tempo pela SUN, com a "SUN Grid Engine", ou pela Hewlett Packard, com a "HPC utilities", nomeadamente para:
-
DEISA - Distrubuted European Infrastrcture for Supercomputing Applications
-
EGEEE - Enabling Grid for E-sciencE[6], que liga mais de 180 centros de cálculos europeus e mundiais a partir de uma larga extensão de Globus, a Globus Toolkit,[7] no quadro do projeto europeu Datagrid[8] do CERN apoiado pelos mediadores (middleware) empregados na LCG.
Grelhas/Grades
No meio científico já pode-se encontrar várias grades em funcionamento espalhados por vários países, muitos sendo projetos multi-institucionais. Como exemplos tem-se:
-
EGI (European Grid Infrastructure)
-
Datagrid, do CERN, um projeto financiado pela Comunidade Europeia com o objetivo de atuar em áreas de pesquisa como astronomia, física e biologia;
-
BIRN, projeto multi-institucional que conta com quinze universidades norte-americanas, voltado para a pesquisa neurológica
-
Mammogrid, uma iniciativa da comunidade européia para formar uma base de mamografias que abrange toda a Europa com intuito de fornecer material de estudo e campo para o desenvolvimento de tecnologias em grade.
Quem pode usar grade de informatica
Governos e Organizações Internacionais
Militares
Professores e educadores
Empresas
Ciclos de processamento são os recursos compartilhados neste tipo. Existem três formas de explorar os recursos computacionais em um grade:
● executar uma aplicação em qualquer máquina disponível do grade, independentemente de onde esteja localizada;
● quebrar o aplicativo em partes menores para que estas possam ser executadas paralelamente através do grade;
● executar uma tarefa que precisa rodar várias vezes em diferentes máquinas do grade.
Este tipo de grade tem como principal funcionalidade prover serviços de comunicação tolerantes a falhas e com alta performance. Máquinas com conexões ociosas podem ser
utilizadas para enviar porções de dados ou prover redundância nas transmissões
O espaço de armazenamento disponível em cada máquina é compartilhado pelo grade. Desta forma aumenta a capacidade de armazenamento como um todo, além de aumentar a
performance, compartilhamento e confiabilidade dos dados. Utilizando todo o espaço como se fosse um sistema de arquivos só para todo o grade facilita a localização de
determinado arquivo, sendo que este pode estar dividido em partes menores e espalhado pelas máquinas participantes. Sistemas de gerenciamento podem duplicar dados sensíveis
em várias máquinas provendo uma redundância.
A utilização de padrões é um requisito para os grades. Os padrões estão sendo desenvolvidos pelo Global Grade Forum, uma entidade que possui centenas de membros, representando
mais de 400 organizações e empresas em mais de 50 países. Os padrões desenvolvidos:
● Open Grade Services Architecture (OGSA): define o que são os serviços e toda a estrutura que pode ser provida em um ambiente grade . É baseada nos padrões já definidos para os Web Services e considera um serviço em um grade como um Web Service com algumas particularidades.
● Open Grade Services Infrastructure (OGSI): OGSI é a especificação concreta da infraestrutura da OGSA. Baseado nas tecnologias de grades e Web Services, é o middleware para os chamados grade services, ou serviços do grade, definindo como construir, gerenciar e expandir um serviço.
● Novos padrões estão sendo desenvolvidos e aprimorados.
● Globus Toolkit : implementação das especificações OGSA/OGSI. Bindings para C e Java. Usando os Commodity Grade Toolkits é possível trabalhar em outras linguagens como Python, Perl, entre outras.
● IBM Grade Toolbox : versão comercial do Globus. C e Java
● Legion
● Ourgrade : projeto brasileiro desenvolvido pela Universidade Federal de Campina Grande.
● Ferramentas comerciais: Platform LSF, Avaki Grade Server,
● Diversas ferramentas para portais de grades: Grade Portal Development Kit. Legion Grade Portal. GridPort. Sun Techical Computing Portal. GridSphere.
Principais Projetos de Grade:
● ChinaGrid (interligação de universidades e governo)
● Projeto eDiamond (processamento de mamografias)
● Molecular Modeling Laboratory – UNC (desenvolvimento de drogas)
● DEISA (interligação de laboratórios científicos)
● AccessGrid (video conferência e e-learning)
● TeraGrid (interligação de universidades)
● World Community Grade (utilização de processamento de desktops para vários projetos)
No Brasil um bom exemplo é o Sprace, projeto de um grade do Instituto de Física da USP que participa no processamento dos dados provenientes do projeto D0 (projeto que reúne pesquisadores do mundo todo para analisar os dados gerados pelo acelerador de alta energia Tevatron Collider, localizado em Illinois, Estados Unidos).
A tecnologia em grade vem sendo aperfeiçoada, em grande parte pelo esforço do Global Grid Forum (GGF), uma comunidade formada por entidades do meio científico e corporativo que criam e padronizam tecnologias para ambientes em grade. Um dos trabalhos mais importantes do GGF atualmente vem sendo o desenvolvimento do OGSA (Open Grid Service Architecture), um padrão cujo objetivo é permitir interoperabilidade, portabilidade e reutilização de serviços em grade através da padronização de interfaces, comportamentos e serviços básicos obrigatórios, APIs, etc, assim viabilizando a utilização conjunta de serviços desenvolvidos em diferentes ambientes, por diferentes desenvolvedores.
Pesquisadores da área acreditam que a tecnologia de grades computacionais seja a evolução dos sistemas computacionais atuais, não sendo apenas um fenômeno tecnológico mas também social pois num futuro próximo reuniria recursos e pessoas de várias localidades, com várias atividades diferentes, numa mesma infra-estrutura possibilitando sua interação de uma forma antes impossível.
CLOUD COMPUTING
O conceito de computação em nuvem (em inglês, cloud computing) refere-se à utilização da memória e da capacidade de armazenamento e cálculo de computadores e servidores Hospedados em Datacenter e interligados por meio da Internet, seguindo o princípio da computação em grade. [1]
O armazenamento de dados é feito em serviços que poderão ser acessados de qualquer lugar do mundo, a qualquer hora, não havendo necessidade de instalação de programas ou de armazenar dados. O acesso a programas, serviços e arquivos é remoto, através da Internet - daí a alusão à nuvem.[2] O uso desse modelo (ambiente) é mais viável do que o uso de unidades físicas.[3]
Num sistema operacional disponível na Internet, a partir de qualquer computador e em qualquer lugar, pode-se ter acesso a informações, arquivos e programas num sistema único, independente de plataforma. O requisito mínimo é um computador compatível com os recursos disponíveis na Internet. O PC torna-se apenas um chip ligado à Internet — a "grande nuvem" de computadores — sendo necessários somente os dispositivos de entrada (teclado, rato/mouse) e saída (monitor).
Corrida pela tecnologia
Empresas como Amazon, Oracle, Google, IBM e Microsoft foram as primeiras a iniciar uma grande ofensiva nessa "nuvem de informação" (information cloud), que especialistas consideram uma "nova fronteira da era digital". Aos poucos, essa tecnologia vai deixando de ser utilizada apenas em laboratórios para ingressar nas empresas e, em breve, em computadores domésticos.
O primeiro serviço na Internet a oferecer um ambiente operacional para os usuários—antigamente, disponível no endereço www.webos.org—foi criado por um estudante sueco, Fredrik Malmer, utilizando as linguagens XHTML e Javascript.
Em 1999, foi criada nos EUA a empresa WebOS Inc., que comprou os direitos do sistema de Fredrik e licenciou uma série de tecnologias desenvolvidas nas universidades do Texas, Califórnia e Duke.
Tipologia
Atualmente, a computação em nuvem é dividida em dez tipos:
-
IaaS - Infrastructure as a Service ou Infraestrutura como Serviço (em português): contém os componentes básicos da TI em nuvem e, geralmente, dá acesso à recursos de computação e armazenamento baseados na Internet. Sendo a categoria mais básica entre os tipos de computação em nuvem, a IaaS permite que você alugue uma infraestrutura de TI (servidores e máquinas virtuais, armazenamento, redes e sistemas operacionais) de um provedor de nuvem em uma base paga conforme o uso.(p.ex.: Goole Drive, Amazon AWS).[4]
-
PaaS - Plataform as a Service ou Plataforma como Serviço (em português): dá aos desenvolvedores as ferramentas necessárias para criar e hospedar aplicativos Web. A PaaS foi desenvolvida para proporcionar aos usuários o acesso aos componentes necessários para desenvolver e operar rapidamente aplicativos Web ou móveis na Internet, sem se preocupar com a configuração ou gerenciamento da infraestrutura subjacente dos servidores, armazenamento, redes e bancos de dados.. (p.ex.: IBM Bluemix, Windows Azure e Jelastic).[4]
-
DaaS - Desktop as a Service ou Área de trabalho como serviço (em português): O desktop como serviço (DaaS) é uma solução de computação em nuvem na qual a infraestrutura de desktop virtual é terceirizada para um provedor terceirizado. A funcionalidade DaaS conta com o desktop virtual, que é uma sessão controlada pelo usuário ou uma máquina dedicada que transforma serviços de nuvem sob demanda para usuários e organizações em todo o mundo. Esse é um modelo eficiente no qual o provedor de serviços gerencia todas as responsabilidades de back-end que normalmente seriam fornecidas pelo software aplicativo.Desktop como um serviço também é conhecido como desktop virtual ou serviços de desktop hospedados. O DaaS facilita o gerenciamento de vários tipos de recursos de computadores, incluindo desktops, laptops, unidades de mão e thin clients. O DaaS usa execução distribuída ou execução remota, dependendo do tipo de implementação. O DaaS é uma alternativa econômica para soluções de TI convencionais e é usado por organizações e empresas que exigem altos níveis de desempenho e disponibilidade. Além disso, o DaaS serve como uma solução ideal para pequenas organizações com recursos limitados.[5]
-
SaaS - Software as a Service ou Software como Serviço (em português): O software como um serviço oferece um produto completo, executado e gerenciado pelo provedor de serviços. Na maioria dos casos, as pessoas que se referem ao software como um serviço estão se referindo às aplicações de usuário final. Com uma oferta de SaaS, não é necessário pensar sobre como o serviço é mantido ou como a infraestrutura subjacente é gerenciada, você só precisa pensar em como usará este tipo específico de software.(p.ex.: Google Docs , Microsoft SharePoint Online).[6]
-
CaaS - Communication as a Service ou Comunicação como Serviço (em português): uso de uma solução de Comunicação Unificada hospedada em Data Center do provedor ou fabricante (p.ex.: Microsoft Lync).
-
XaaS - Everything as a Service ou Tudo como Serviço (em português): quando se utiliza tudo, infraestrurura, plataformas, software, suporte, enfim, o que envolve T.I.C. (Tecnologia da Informação e Comunicação) como um Serviço. Tudo como um serviço oferece a flexibilidade para que usuários e empresas personalizem seus ambientes de computação para criar as experiências que desejam, tudo sob demanda. O XaaS é dependente de uma forte plataforma de serviços em nuvem e conectividade confiável à Internet para ganhar com sucesso tração e aceitação entre indivíduos e empresas.[7]
-
DBaas - Data Base as a Service ou Banco de dados como Serviço (em português): O nome já deixa claro que essa modalidade é direcionada ao fornecimento de serviços para armazenamento e acesso de volumes de dados. A vantagem aqui é que o detentor da aplicação conta com maior flexibilidade para expandir o banco de dados, compartilhar as informações com outros sistemas, facilitar o acesso remoto por usuários autorizados, entre outros;[8]
-
SECaaS - Security as a Service - ou Segurança como Serviço (em português): é um modelo de negócio, onde o provedor de serviço integra serviços de segurança em uma infraestrutura corporativa por meio mais eficiente do que indivíduos ou corporações podem prover por si próprias - quando o custo total de posse é considerado.[9]
-
FaaS - Function as a Service - ou Função como Serviço (em português): é uma chamada de procedimento remoto hospedada em serviço que aproveita a computação sem servidor para permitir a implementação de funções individuais na nuvem que são executadas em resposta a eventos.[10] O FaaS está incluído no termo mais amplo computação sem servidor, mas os termos também podem ser usados de forma intercambiável.[11]
-
MBaaS - Mobile "backend" as a Service - ou Backend móvel como Serviço (em português): também conhecido como Backend como um Serviço (BaaS), os desenvolvedores de aplicativos móveis e de aplicativos web são providos com uma maneira de vincular seus aplicativos a serviços de armazenamento em nuvem e computação em nuvem com Interface de programação de aplicações (APIs) expostas às suas aplicações e Kit de desenvolvimento de software personalizado (SDK). Os serviços incluem gerenciamento de usuários, notificações por push, integração com serviços de redes sociais[12], entre outros. Esse é um modelo relativamente recente na computação em nuvem,[13] com a maioria das startups de BaaS datadas de 2011 ou posteriores[14][15][16], mas as tendências indicam que esses serviços estão ganhando tração significativa junto aos consumidores corporativos.[17]
Serviços oferecidos
Os seguintes serviços atualmente são oferecidos por empresas:
Característica de computação em nuvem
-
Provisionamento dinâmico de recursos sob demanda, com mínimo de esforço;
-
Escalabilidade;
-
Uso de "utility computing", onde a cobrança é baseada no uso do recurso ao invés de uma taxa fixa;
-
Visão única do sistema;
-
Distribuição geográfica dos recursos de forma transparente ao usuário.
Modelo de implantação
A adoção de sistemas cloud computing dependem das características tecnologicas e do modo como os utilizadores percecionam a utilidade da cloud. Por exemplo se os sistemas cloud forem faceis de usar e se acrescentarem utilidade aos utilizadores finais, estes tendem a usar sistemas cloud [18]. Para auxiliar na decisão do utilizador final na escolha do modelo cloud, o utilizador deverá identificar a adequação da infraestrutura tecnológica, devrá mensurar os custos e o retorno desse investimento, bem como identificar as medidas de controlo de integridade de informação, a usabilidade da informação e dos sistemas.
Neste contexto, importa ainda identificar as medidas de fiabilidade e segurança e integridade dos sistemas da informação e dos dados.[19] No modelo de implantação,[20] dependemos das necessidades das aplicações que serão implementadas. A restrição ou abertura de acesso depende do processo de negócios, do tipo de informação e do nível de visão desejado. Percebemos que certas organizações não desejam que todos os usuários possam acessar e utilizar determinados recursos no seu ambiente de computação em nuvem. Segue abaixo a divisão dos diferentes tipos de implantação:
Nuvem privada
As nuvens privadas são aquelas construídas exclusivamente para um único usuário (uma empresa, por exemplo). Diferentemente de um data center privado virtual, a infraestrutura utilizada pertence ao usuário, e, portanto, ele possui total controle sobre como as aplicações são implementadas na nuvem. Uma nuvem privada é, em geral, construída sobre um data center privado.
Nuvem pública
Uma nuvem é chamada de "nuvem pública" quando os serviços são apresentados por meio de uma rede que é aberta para uso público. Serviços de nuvem pública podem ser livres. Tecnicamente pode haver pouca ou nenhuma diferença entre a arquitetura de nuvem privada e pública, entretanto, considerações de segurança podem ser substancialmente diferentes para os serviços (aplicações, armazenamento e outros recursos) que são disponibilizados por um provedor de serviços para um público e quando a comunicação é afetada sobre uma rede não confiável.
Geralmente, provedores de serviços de nuvem pública como a Amazon AWS, Microsoft e Google possuem e operam a infraestrutura em seus centros de dados e o acesso geralmente é feito por meio da Internet. A AWS e a Microsoft também oferecem serviços conectados diretamente chamados "AWS Direct Connect" e "Azure ExpressRoute" respectivamente. Tais conexões necessitam que os clientes comprem ou aluguem uma conexão privada ao um ponto de troca de tráfego oferecido pelo provedor de nuvem.
As aplicações de diversos usuários ficam misturadas nos sistemas de armazenamento, o que pode parecer ineficiente a princípio. Porém, se a implementação de uma nuvem pública considera questões fundamentais, como desempenho e segurança, a existência de outras aplicações sendo executadas na mesma nuvem permanece transparente tanto para os prestadores de serviços como para os usuários.
Nuvem híbrida
Nas nuvens híbridas temos uma composição dos modelos de nuvens públicas e privadas. Elas permitem que uma nuvem privada possa ter seus recursos ampliados a partir de uma reserva de recursos em uma nuvem pública. Essa característica possui a vantagem de manter os níveis de serviço mesmo que haja flutuações rápidas na necessidade dos recursos. A conexão entre as nuvens pública e privada pode ser usada até mesmo em tarefas periódicas que são mais facilmente implementadas nas nuvens públicas, por exemplo. O termo computação em ondas é, em geral, utilizado quando se refere às nuvens híbridas.
Outros
Nuvem comunitária
A nuvem comunitária é de uso exclusivo para específicas comunidades de consumidores de organizações com interesses compartilhados (Requerimentos de segurança, política, considerações de compliance, entre outros). Ela pode ser gerenciada por uma ou mais organizações na comunidade, por terceiros, ou por alguma combinação entre eles, e podem ser hospedadas tanto internamente ou externamente. Seu custo por usuários é maior a Nuvem pública (porém, menor do que na Nuvem privada), então apenas alguns recursos de menor custo da computação em nuvem podem ser aplicados. [21]
Nuvem HPC
Nuvem HPC se refere ao uso dos serviços e infraestrutura da computação em nuvem para executar aplicações de alta performance (em inglês, High Performance Computing Cloud ou HPC Cloud)[22]. Essas aplicações consomem uma porção considerável de poder de computação e de memória, e são tradicionalmente aglomerados de computadores. Vários vendedores oferecem servidores que suportam a execução dessas aplicações. [23][24][25][26]
Em nuvem HPC, o modelo de implantação permite que todos os recursos de HPC estejam dentro da infraestrutura do provedor da nuvem ou em diferentes porções de recursos HPC à serem compartilhados entre o provedor e o cliente no local em que a infraestrutura se encontra. A implementação de nuvem para rodar aplicações de alta performance (HPC applications) começou majoritariamente para aplicações compostas de tarefas independentes, sem inter-process communication (IPC). Conforme os provedores de nuvens começaram a oferecer tecnologias de rede de alta velocidade, como a InfiniBand, aplicações com multiprocessamento totalmente acoplados começaram a se beneficiar dos serviços de nuvem também.
Multicloud
O Multicloud é o uso de vários serviços de computação em nuvem em uma única arquitetura heterogênea para reduzir a dependência de fornecedores individuais, aumentar a flexibilidade por meio de opções, mitigar desastres etc. Diferencia-se da nuvem híbrida em se referir a vários serviços em nuvem, em vez de várias implantações modos (público, privado, legado). [27][28][29]
Nuvem de BigData
Os problemas para transferir grandes quantidades de dados para a nuvem, assim como segurança desses dados uma vez que esses dados estão na nuvem inicialmente dificultaram a implementação de nuvem para Big Data, mas agora que muitos dados se originam na nuvem e com o advento dos servidores bare-metal, a nuvem se tornou[30] uma solução para usada para diversos casos, incluindo análise de negócios (business analytics) e análises geoespaciais (geospatial analysis).[31]
Nuvem Distribuída
Uma plataforma de computação em nuvem pode ser montada por máquinas distribuídas em diferentes locais, conectadas à uma rede ou à um serviço de hub. Existem dois tipos de nuvem distribuída: computação com recursos públicos (public-resource computing) e nuvem voluntária (volunteer cloud).
● Computação com recursos públicos: Este tipo de nuvem distribuída é resultado de uma extensa definição de computação em nuvem, porque eles são mais semelhantes à nuvem distribuída do que à computação em nuvem. De qualquer forma, esta é considerada uma subclasse da computação em nuvem, e alguns exemplos incluem plataforma distribuídas de computação como: BOINC e Folding@Home.
● Nuvem voluntária: Esta é caracterizada como a interseção entre nuvem distribuída e computação em nuvem, onde a infraestrutura da computação em nuvem é construída utilizando recursos voluntários. Muitos desafios surgem por conta deste tipo de infraestrutura, por causa da volatilidade dos recursos usados para a construção e por conta do ambiente dinâmico em que opera. Esta também pode ser chamada de nuvens de pessoa para pessoa (peer-to-peer cloud), ou nuvens ad-hoc. A Cloud@Home é uma iniciativa interessante nessa direção, ela tem como objetivo implementar uma infraestrutura de computação em nuvem utilizando recursos voluntários provendo um modelo de negócios que incentiva contribuições através de restituição financeira.[32]
Arquitetura
Arquitetura de Nuvem
Arquitetura de nuvem,[33] os sistemas de arquitetura dos sistemas de software envolvidos na entrega da computação em nuvem, tipicamente envolvem múltiplos componentes de nuvem comunicando-se entre si através de um mecanismo de acoplamento solto, como uma fila de mensagens. O fornecimento elástico implica inteligência no uso de acoplamento rígido ou solto aplicado a mecanismos como esses e outros.
Engenharia de Nuvem
Engenharia de nuvem é a aplicação de disciplinas de engenharia à computação em nuvem. Essa trás uma abordagem sistemática para as preocupações de alto nível de comercialização, padronização e governança na concepção, desenvolvimento, operação e manutenção de sistemas de computação em nuvem. É um método multidisciplinar que engloba contribuições de diversas áreas, como sistemas, software, web, desempenho, informação, segurança, plataforma, risco e engenharia de qualidade.
Vantagens
A maior vantagem da computação em nuvem é a possibilidade de utilizar softwares sem que estes estejam instalados no computador. Mas há outras vantagens:[34]
-
Na maioria das vezes o usuário não precisa se preocupar com o sistema operacional e hardware que está usando em seu computador pessoal, podendo acessar seus dados na "nuvem computacional" independentemente disso;
-
As atualizações dos softwares são feitas de forma automática, sem necessidade de intervenção do usuário;
-
O trabalho corporativo e o compartilhamento de arquivos se tornam mais fáceis, uma vez que todas as informações se encontram no mesmo "lugar", ou seja, na "nuvem computacional";
-
Os softwares e os dados podem ser acessados em qualquer lugar, basta apenas que haja acesso à Internet, não são mais restritos ao ambiente local de computação, nem dependem da sincronização de mídias removíveis.
-
o usuário tem um melhor controle de gastos ao usar aplicativos, pois a maioria dos sistemas de computação em nuvem fornece aplicações gratuitamente e, quando não gratuitas, são pagas somente pelo tempo de utilização dos recursos. Não é necessário pagar por uma licença integral de uso de software;
-
diminui a necessidade de manutenção da infraestrutura física de redes locais cliente/servidor, bem como da instalação dos softwares nos computadores corporativos, pois esta fica a cargo do provedor do software em nuvem, bastando que os computadores clientes tenham acesso à Internet;
-
a infraestrutura necessária para uma solução de computação em nuvem é bem mais enxuta do que uma solução tradicional de hospedagem ou alojamento, consumindo menos energia, refrigeração e espaço físico e consequentemente contribuindo para a preservação e o uso racional dos recursos naturais.
Desvantagens
A maior desvantagem da computação em nuvem vem fora do propósito desta, que é o acesso a internet. Caso você perca o acesso, comprometerá todos os sistemas embarcados.
-
Velocidade de processamento: caso seja necessário uma grande taxa de transferência, se a internet não tiver uma boa banda, o sistema pode ser comprometido. Um exemplo típico é com mídias digitais ou jogos;
-
Assim como todo tipo de serviço, ele é custeado.
Gerenciamento da segurança da informação na nuvem
Sete princípios de segurança em uma rede em nuvem:[35]
-
Acesso privilegiado de usuários - A sensibilidade de informações confidenciais nas empresas obriga um controle de acesso dos usuários e informação bem específica de quem terá privilégio de administrador, para que então esse administrador controle os acessos
-
Compliance com regulamentação - As empresas são responsáveis pela segurança, integridade e a confidencialidade de seus próprios dados. Os fornecedores de computação em nuvem devem estar preparados para auditorias externas e certificações de segurança.
-
Localização dos dados - A empresa que usa cloud provavelmente não sabe exatamente onde os dados estão armazenados, talvez nem o país onde as informações estão guardadas. O fornecedor deve estar disposto a se comprometer a armazenar e a processar dados em jurisdições específicas, assumindo um compromisso em contrato de obedecer os requerimentos de privacidade que o país de origem da empresa pede.
-
Segregação dos dados - Geralmente uma empresa divide um ambiente com dados de diversos clientes. Procure entender o que é feito para a separação de dados, que tipo de criptografia é segura o suficiente para o funcionamento correto da aplicação.
-
Recuperação dos dados - O fornecedor em cloud deve saber onde estão os dados da empresa e o que acontece para recuperação de dados em caso de catástrofe. Qualquer aplicação que não replica os dados e a infra-estrutura em diversas localidades está vulnerável a falha completa. Importante ter um plano de recuperação completa e um tempo estimado para tal.
-
Apoio à investigação - A auditabilidade de atividades ilegais pode se tornar impossível na computação em nuvem uma vez que há uma variação de servidores conforme o tempo onde estão localizados os acessos e os dados dos usuários. Importante obter um compromisso contratual com a empresa fornecedora do serviço e uma evidência de sucesso no passado para esse tipo de investigação.
-
Viabilidade em longo prazo - No mundo ideal, o seu fornecedor de computação em nuvem jamais vai falir ou ser adquirido por uma empresa maior. A empresa precisa garantir que os seus dados estarão disponíveis caso o fornecedor de computação em nuvem deixe de existir ou seja migrado para uma empresa maior. Importante haver um plano de recuperação de dados e o formato para que possa ser utilizado em uma aplicação substituta.
Revelações da Vigilância pela NSA
Em outubro de 2013 a imprensa publicou, com base nos documentos revelados por Edward Snowden, que através do Programa MUSCULAR, o GCHQ britânico e a NSA secretamente invadiram os principais enlaces de comunicação dos centros de processamento de dados do Yahoo!e do Google ao redor do mundo, tendo acesso aos dados da nuvem de ambos[37]
Um dos slides de uma apresentação da NSA sobre o programa mostra como este funciona e apresenta um rosto com um sorriso indicando o sucesso da NSA em invadir os sistemas alvo. Em palestra em abril de 2014, o jornalista Barton Gellman disse que quando os engenheiros do Google viram o slide, responderam furiosamente ao ataque ao sistema do Google. Foi também este slide um dos fatores importantes em convencer o jornal Washington Post da necessidade e importância de publicar os documentos revelados por Edward Snowden[38] .
Dúvidas
Arquitetura em nuvem é muito mais que apenas um conjunto (embora massivo) de servidores interligados. Requer uma infraestrutura de gerenciamento desse grande fluxo de dados que incluem funções para aprovisionamento e compartilhamento de recursos computacionais, equilíbrio dinâmico do workload e monitoração do desempenho.
Embora a novidade venha ganhando espaço, ainda é cedo para dizer se dará certo ou não. Os arquivos são guardados na web e os programas colocados na nuvem computacional - e não nos computadores em si - são gratuitos e acessíveis de qualquer lugar. Mas a ideia de que 'tudo é de todos e ninguém é de ninguém' nem sempre é algo bem visto. O fator mais crítico é a segurança, considerando que os dados ficam “online” o tempo todo.
Sistemas atuais
Os sistemas operacionais para Internet mais utilizados são:
-
Google Chrome OS: Desenvolvido pela Google, já incorporado nos Chromebooks, disponíveis desde 15 de junho de 2011. Trabalha com uma interface diferente, semelhante ao do Google Chrome, em que todas as aplicações ou arquivos são salvos na nuvem e sincronizados com sua conta do Google, sem necessidade de salvá-los no computador, já que o HD dos dois modelos de Chromebooksanunciados contam com apenas 16gb de HD.[39]
-
Joli Os: desenvolvido por Tariq Krim, o ambiente de trabalho chamado jolicloud usa tanto aplicativos em nuvem quanto aplicativos offline, baseado no ubuntu notebook remix, já tem suporte a vários navegadores como google chrome, safari, firefox, e está sendo desenvolvido para funcionar no android.
-
YouOS: desenvolvido pela empresa WebShaka, cria um ambiente de trabalho inspirado nos sistemas operacionais modernos e utiliza a linguagem Javascript para executar as operações. Ele possui um recurso semelhante à hibernação no MS-Windows XP, em que o usuário pode salvar a área de trabalho com a configuração corrente, sair do sistema e recuperar a mesma configuração posteriormente. Esse sistema também permite o compartilhamento de arquivos entre os usuários. Além disso, possui uma API para o desenvolvimento de novos aplicativos, sendo que já existe uma lista de mais de 700 programas disponíveis. Fechado pelos desenvolvedores em 30 de julho de 2008;
-
DesktopTwo: desenvolvido pela empresa Sapotek, tem como pré-requisito a presença do utilitário Flash Player para ser utilizado. O sistema foi desenvolvido para prover todos os serviços necessários aos usuários, tornando a Internet o principal ambiente de trabalho. Utiliza a linguagem PHP como base para os aplicativos disponíveis e também possui uma API, chamada Sapodesk, para o desenvolvimento de novos aplicativos. Fechado para desenvolvedores;
-
G.ho.st: Esta sigla significa “Global Hosted Operating SysTem” (Sistema Operacional Disponível Globalmente), tem como diferencial em relação aos outros a possibilidade de integração com outros serviços como: Google Docs, Meebo, ThinkFree, entre outros, além de oferecer suporte a vários idiomas;
-
eyeOS: Este sistema está sendo desenvolvido por uma comunidade denominada EyeOS Team e possui o código fonte aberto ao público. O objetivo dos desenvolvedores é criar um ambiente com maior compatibilidade com os aplicativos atuais, MS-Office e OpenOffice. Possui um abrangente conjunto de aplicativos, e o seu desenvolvimento é feito principalmente com o uso da linguagem PHP.
-
iCloud: Sistema lançado pela Apple em 2011, é capaz de armazenar até 5 GB de fotos, músicas, documentos, livros e contatos gratuitamente, com a possibilidade de adquirir mais espaço em disco (pago).
-
Ubuntu One: Ubuntu One é a suíte que a Canonical (Mantenedora da distribuição Linux Ubuntu) usa para seus serviços online. Atualmente com o Ubuntu One é possível fazer backups, armazenamento, sincronização e compartilhamento de arquivos e vários outros serviços que a Canonical adiciona para oferecer mais opções e conforto para os usuários.
-
IBM Smart Business: Sistema da IBM que engloba um conjunto de serviços e produtos integrados em nuvem voltados para a empresa. O portfólio incorpora sofisticada tecnologia de automação e autosserviço para tarefas tão diversas como desenvolvimento e teste de software, gerenciamento de computadores e dispositivos, e colaboração. Inclui o Servidor IBM CloudBurst server (US) com armazenamento, virtualização, redes integradas e sistemas de gerenciamento de serviço embutidos.
-
Dropbox: Dropbox é um sistema de armazenamento em nuvem que inicia-se gratuitamente com 2gb e conforme indica amigos o espaço para armazenamento de arquivos cresce até 50gb. Também tem opções pagas com maior espaço.
-
OneDrive: Serviço de armazenamento em nuvem da Microsoft com 5gb free e com a possibilidade de adquirir mais espaço. Tem serviços sincronizados com o windows 8, windows phone e Xbox.
No Brasil
No Brasil, a tecnologia de computação em nuvem é muito recente, mas está se tornando madura muito rapidamente. Empresas de médio, pequeno e grande porte estão adotando a tecnologia gradativamente. O serviço começou a ser oferecido comercialmente em 2008 e em 2012, ocorreu uma grande adoção.
A empresa Katri[40] foi a primeira a desenvolver a tecnologia no Brasil, em 2002, batizando-a IUGU. Aplicada inicialmente no site de busca de pessoas físicas e jurídicas Fonelista. Durante o período em que esteve no ar, de 2002 a 2008, os usuários do site puderam comprovar a grande diferença de velocidade nas pesquisas proporcionada pelo processamento paralelo.
Em 2009, a tecnologia evoluiu muito, e sistemas funcionais desenvolvidos no início da década já passam de sua 3ª geração, incorporando funcionalidades e utilizando de tecnologias como "índices invertidos" (inverted index). No ambiente acadêmico o Laboratório de Redes e Gerência da UFSC foi um dos pioneiros a desenvolver pesquisas em Computação em Nuvem publicando artigos sobre segurança, IDS (Intrusion Detection Systems) e SLA (Service Level Agreement) para computação em nuvem. Além de implantar e gerenciar uma nuvem privada e computação em nuvem verde.
Nuvens públicas
Existem pouco menos de 10 empresas ofertantes do serviço em nuvens públicas (que podem ser contratadas pela internet em estrutura não privativa e com preços e condições abertas no site) com servidores dentro do Brasil e com baixa latência. A maioria utiliza tecnologia baseada em Xen, KVM, VMWare, Microsoft Hypervisor.
